
A ReplicaSet’s purpose is to maintain a stable set of replica Pods running at any given time. Usually, you define a Deployment and let that Deployment manage ReplicaSets automatically.
A ReplicaSet’s purpose is to maintain a stable set of replica Pods running at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods
A ReplicaSet is a Kubernetes controller whose primary purpose is to maintain a specified number of identical Pods called replicas. It acts as a self-healing mechanism, if a Pod fails, crashes, or is deleted, the ReplicaSet controller will immediately start a new one to bring the count back to the desired state. This ensures high availability and reliability for your applications.
Purpose of a ReplicaSet
The core function of a ReplicaSet revolves around ensuring application stability and scalability.
- High Availability: By maintaining a minimum number of running Pods, a ReplicaSet ensures that your application can survive node failures or Pod crashes. If one instance goes down, others are still available to serve traffic, preventing downtime.
- Load Balancing: When combined with a Kubernetes Service, a ReplicaSet allows you to distribute network traffic across its set of identical Pods. As you scale the number of replicas up or down, the Service automatically adjusts, ensuring efficient resource utilization.
- Scalability: You can easily scale your application by simply changing the
replicasfield in the ReplicaSet definition. The controller will automatically create or terminate Pods to match the new desired count.
How ReplicaSets Overcame Past Limitations
ReplicaSets are the direct successor to the older Replication Controller. The single most important improvement they offer is more expressive and flexible selectors.
- Replication Controllers use equality-based selectors. This means they can only match Pods that have the exact same key-value pairs in their labels (e.g.,
app: frontend). This is quite restrictive. - ReplicaSets use set-based selectors. This allows for more complex selection criteria. You can match Pods based on whether a label key exists, or if a key’s value is within a specific set of values.
For example, a ReplicaSet can manage Pods where the environment label is either production or qa (environment in (production, qa)). This powerful selection capability makes ReplicaSets far more versatile for managing complex application deployments.
How a ReplicaSet Works
A ReplicaSet in Kubernetes ensures that a specific number of Pod replicas are always running within a cluster. It is defined using key fields such as a selector, a replica count, and a Pod template. The selector determines which Pods the ReplicaSet should manage, while the replica count specifies the desired number of Pods that must always be active. The Pod template contains the configuration for new Pods that the ReplicaSet will create if the number of running Pods falls short of the desired count.
To maintain the desired state, the ReplicaSet continuously monitors the number of Pods that match its selector. If there are fewer Pods than specified, the ReplicaSet creates new Pods using its Pod template. If there are more Pods than required, it terminates the extra ones. This mechanism guarantees that the application workload is always consistent and available.
A ReplicaSet maintains ownership of its Pods through the metadata.ownerReferences field. This field links the Pods back to the ReplicaSet, clearly indicating which controller is responsible for managing them. With this ownership reference, the ReplicaSet can track the status of its Pods and decide whether new Pods need to be created or existing ones removed.
When to use a ReplicaSet
A ReplicaSet ensures that a specified number of pod replicas are running at any given time. However, a Deployment is a higher-level concept that manages ReplicaSets and provides declarative updates to Pods along with a lot of other useful features. Therefore, we recommend using Deployments instead of directly using ReplicaSets, unless you require custom update orchestration or don’t require updates at all.
This actually means that you may never need to manipulate ReplicaSet objects: use a Deployment instead, and define your application in the spec section
Example
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-replicaset
spec:
replicas: 2
selector:
matchLabels:
app: nginx-rs-pod
matchExpressions:
- key: env
operator: In
values:
- dev
template:
metadata:
labels:
app: nginx-rs-pod
env: dev
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
Non-Template Pod Acquisitions
You need to make sure that the selectors which are mentioned in the replicaset don’t match other pod labels. ReplicaSet has the ability to acquire pods that are not created by itself as long as the selector doesn’t match other pod labels. This is known as non-template pod acquisitions.
Example
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: 1st-replicaset
spec:
podSelector:
matchLabels:
app: Web-app
replicas: 5
Replicaset will acquire the pods which are having the same label as mentioned in the manifestfile. It will manage all the pods and monitor all the pods with the same labels
Working with ReplicaSets
Step 1: Create a YAML file that defines the ReplicaSet. This file should include the number of replicas you want, the container image to use, and any other desired properties such as environment variables or resource limits.
To create the ReplicaSet, you can use the kubectl create command and pass it to the YAML file as an argument:
$ kubectl create -f replica.yaml
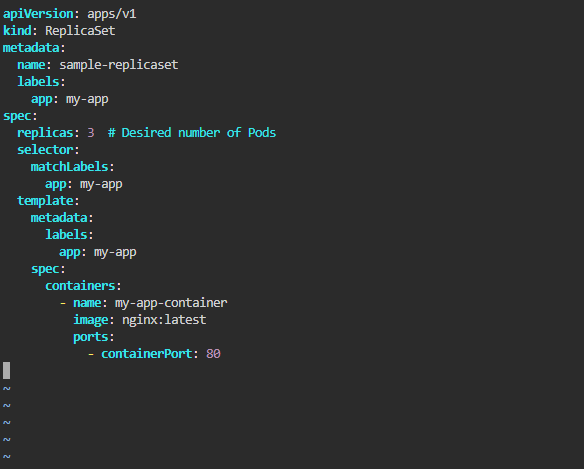

Writing a ReplicaSet manifest
- The apiVersion field specifies the version of the Kubernetes API that the object is using.
- The kind field specifies the type of object that this file represents. In this case, it is a ReplicaSet.
- The metadata field contains metadata about the ReplicaSet, such as its name.
- The spec field contains the specification for the ReplicaSet. It includes the following fields:
- replicas: the number of replicas of the pod that should be running at any given time
- selector: a label query that determines which pods should be managed by the ReplicaSet
- template: the pod template that will be used to create new pods when the ReplicaSet needs to scale up or down. The template field contains the following fields:
- metadata: metadata for the pod
- spec: the specification for the pod. The spec field for the pod includes a containers field, which specifies the containers that should be run in the pod. In this case, there is a single container named my-app that is based on the my-app: latest image and exposes port 80.
Step 2: Verify that the ReplicaSet was created
$ kubectl get replicasets
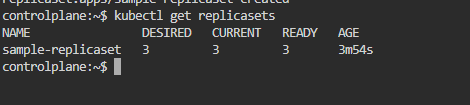
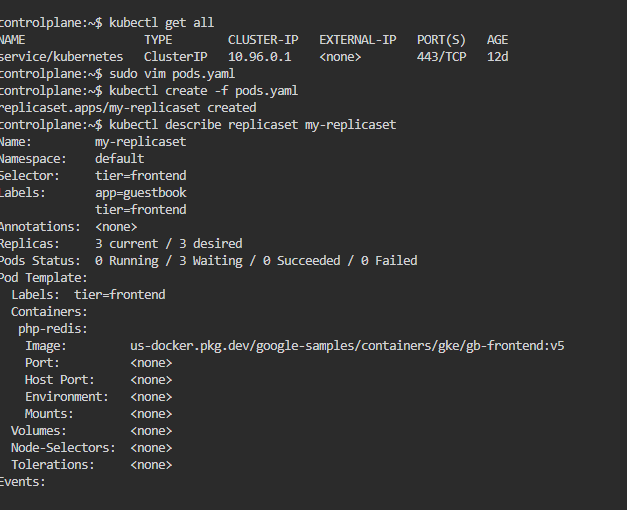
Step 3: View the ReplicaSet in more detail
$ kubectl describe replicaset my-replicaset
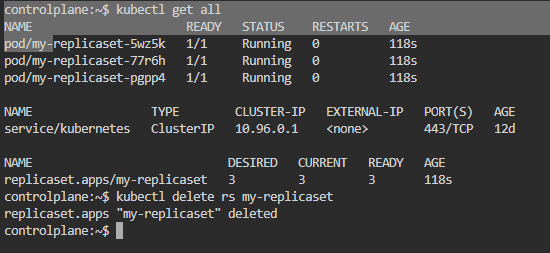
Deleting a ReplicaSet and its Pods
Deleting a ReplicaSet
Replicaset can be deleted by using the following command:
kubectl delete rs <name of the replicaset>Kubectl is a command line interface that will help you to connect to the kubernetes cluster and rs is the short name of replicaset.
Deleting The Pod
The pod can be deleted by using the following command.
kubectl delete pods --selector <key= pair>You can delete the pod without deleting the replicaset by using the above command. If you want to update the pods then you need to delete the pod and then again redeploy it because the replicaset will not support the rolling updates of the pod.
Isolating Pods from a ReplicaSet
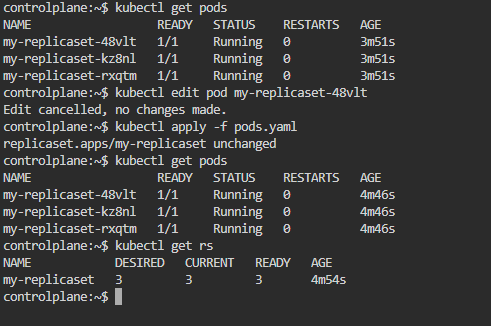
You can isolate a Pod from a ReplicaSet by updating its labels so they no longer match the ReplicaSet’s selector. First, list all Pods to identify the one you want to isolate:
kubectl get podsNext, modify the Pod’s labels to remove or change those matching the ReplicaSet’s selector:
kubectl edit pod <pod-name>Finally, apply the updated configuration to the Pod:
kubectl apply -f <pod-file>.yamlAfter changing the labels, the ReplicaSet stops managing that Pod, effectively isolating it from its replicas.
Scaling a ReplicaSet
You can scale a ReplicaSet either manually or automatically using a Horizontal Pod Autoscaler (HPA).
1. Manual Scaling
To adjust the number of replicas manually, run this command:
kubectl scale rs <replicaset-name> --replicas=5Here, kubectl communicates with your Kubernetes cluster. The scale rs command modifies the ReplicaSet, and the --replicas flag sets the desired number of Pods. Kubernetes then adds or removes Pods to match this new count.
2. Scaling with HPA
A Horizontal Pod Autoscaler can dynamically adjust the number of Pods based on CPU, memory, or custom metrics. Configuring the ReplicaSet as an HPA target ensures your application automatically handles workload changes efficiently.
Difference Between ReplicaSet and ReplicationController
| ReplicaSet | ReplicationController |
|---|---|
| ReplicaSet is the next-generation Replication Controller. | Replication Controller is one of the key features of Kubernetes, which is responsible for managing the pod lifecycle. |
| ReplicaSet will ensure that no.of pods running is matching the desired no. of pods in the Kubernetes cluster. | ReplicationController is responsible for making sure that the specified number of pod replicas are running at any point in time. |
| ReplicaSet supports the new set-based selector requirements as described in the labels user guide whereas a Replication Controller only supports equality-based selector requirements. | Replication Controllers and PODS are associated with labels. |
Difference Between ReplicaSet and DaemonSet
| ReplicaSet | DaemonSet |
|---|---|
| ReplicaSet will ensure that no.of pods running is matching the desired no. of pods in the Kubernetes cluster on any node. | DaemonSet will ensure that each node has at least one pod of the application which we deployed. |
| It is most suitable for applications like web applications which are stateless. | It is most suitable for the application which is stateful. |
| If the pod is deleted automatically replicaset will automatically create a new copy of that pod. | When a new node is added to the cluster daemonset make sure a copy of the pod is added to that node. |
Conclusion
ReplicaSet plays a crucial role in Kubernetes by ensuring that the desired number of Pod replicas are always running in the cluster. It provides self-healing capabilities by automatically replacing failed or terminated Pods and helps maintain application availability. While ReplicaSet is powerful for managing Pod replicas, it is rarely used directly—most often, it is managed indirectly through higher-level controllers like Deployments. In short, ReplicaSet ensures reliability, fault tolerance, and scalability for containerized applications, making it a fundamental building block in Kubernetes workloads.
