
A Kubernetes Deployment is a high-level resource used to manage and scale applications while ensuring they remain in the desired state. It provides a declarative way to define how many Pods should run, which container images they should use, and how updates should be applied.
With a Deployment, you can:
- Scale applications up or down based on demand.
- Maintain reliability, ensuring the desired number of Pods are always running and healthy.
- Perform rolling updates to introduce new versions without downtime.
- Rollback easily if an update causes issues.
Think of it as both a blueprint and controller for Pods that simplifies application management in Kubernetes
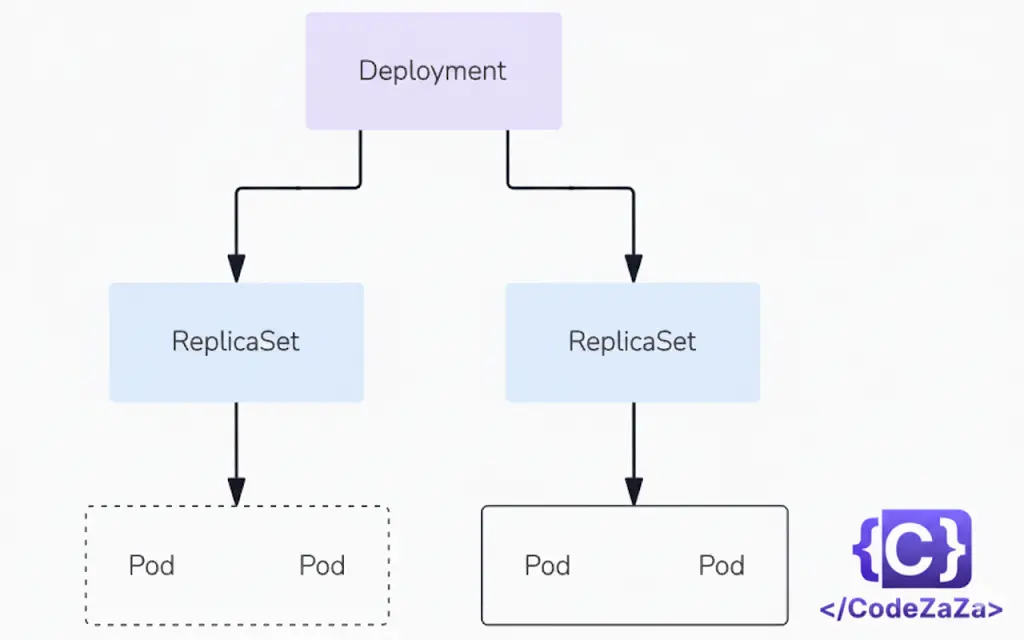
Use Cases of Kubernetes Deployments
Kubernetes Deployments are widely used to manage application lifecycles in a cluster. Typical use cases include:
- Rolling out new applications → Create a Deployment that launches a ReplicaSet, which in turn provisions Pods in the background. You can monitor the rollout status to verify success.
- Updating applications seamlessly → Modify the
PodTemplateSpecin a Deployment to trigger a new ReplicaSet. The Deployment gradually scales the new ReplicaSet up while scaling the old one down, replacing Pods at a controlled pace. Each update increments the Deployment’s revision. - Rolling back safely → Revert to a previous Deployment revision if the current rollout fails or becomes unstable. Each rollback generates a new revision.
- Scaling with demand → Increase or decrease replicas in a Deployment to handle varying traffic loads.
- Pausing and resuming rollouts → Temporarily pause a Deployment to apply multiple fixes to the Pod template, then resume it to roll out all changes at once.
- Monitoring rollout status → Use the Deployment’s status field to detect if a rollout is progressing or stuck.
- Cleaning up resources → Remove outdated ReplicaSets that are no longer needed to keep the cluster tidy and efficient.
What are the essential components of a Kubernetes deployment YAML file?
A Kubernetes deployment YAML file must include key components to define how an application is deployed and managed. The essential elements are:
apiVersion: Specifies the API version, typicallyapps/v1for deployments.- kind: Defines the resource type, set to
Deployment. metadata: Contains identifying information likenameand optionallabels.- spec: Outlines the desired state of the deployment, including:
replicas: Number of pod instances.selector: Match criteria to link the deployment with its pods.template: Pod template specification containing:metadata: Pod labels.spec: Container details such ascontainers, each withname,image,ports, and possiblyenv,volumeMounts, etc.
For example, without selector, the deployment will fail, and missing containers details will prevent pod creation. These components ensure the deployment controller can manage pod lifecycle and scaling effectively
Kubernetes Deployment YAML
We will be using Minikube to use Kubernetes on our local machine. The Deployment configuration file for Nginx will be:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "128Mi"
cpu: "500m"
ports:
- containerPort: 80
Now first open the directory where you have created nginx.yaml file in your terminal and create deployment using the command:
$ kubectl apply -f nginx.yaml
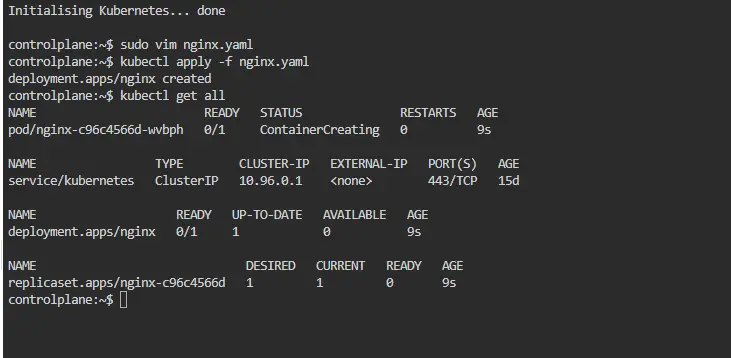
Now check the status of your deployment if it is ready or not by running the command
$ kubectl get all
Hence we have successfully deployed created a deployment for Nginx.
Updating a Kubernetes Deployment
To update a Kubernetes deployment we can simply update its config file using 2 methods:
Method 1: Using the kubectl edit command from the terminal
$ kubectl edit deployment deployment-name
Now you can edit the deployment configuration by pressing “i” for inserting and after editing it you can just press the escape key and then “:wq” to save your changes and exit.
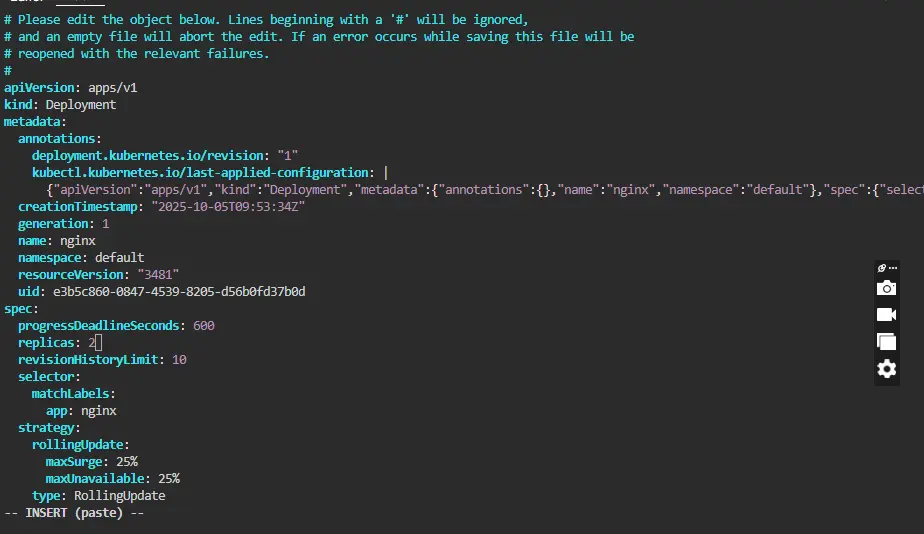
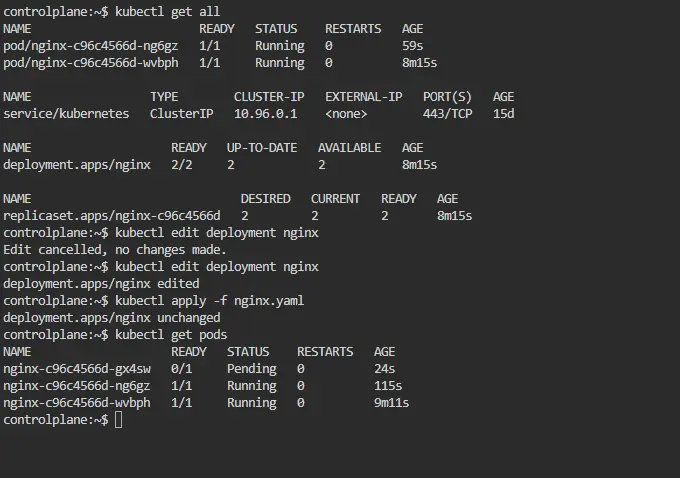
Method 2: Updating Configuration Directly
You can open your config file in an IDE like VS Code and edit the config there and apply the config by using the command
$ kubectl apply -f deployment_config.yaml
Let’s say in this case we are updating the container port from 80 to 800.
Rolling Back a Kubernetes Deployment
In Kubernetes deployment, you can revert back to the previous version of the application if you find any bugs in the present version. This process helps minimize issues faced by end users in the current or updated version of the application.
The following steps can be followed for rolling back a deployment:
Step 1: List all the revisions by using the following command and choose the version of the deployment you want to roll back to.
kubectl rollout historyStep 2: To roll back to the previous version of the deployment, use the command below. It will revert the deployment to the most recent previous version.
kubectl rollout undo deployment nginx-deployment --to-revision=1(You can mention the required version number.)
Step 3: Reverting to an earlier version of the application helps reduce downtime for customers. It’s important to regularly test and validate your rollback process to ensure its effectiveness in real-world scenarios.
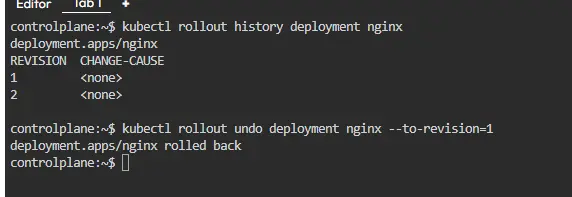
Checking the Rollout History of a Kubernetes Deployment
Rollout history can be seen by using the following command.
kubectl rollout history <name of the deployment>
This command allows you to view the no.of revisions available in the kubernetes cluster and changes made to them. If you want to see the detailed history of a specific version then you use the following command.
kubectl rollout history deployment/web-appdeployment --revision=3
Rollout history will help you to roll to previous versions of the application if you find bugs or problems in the currently deployed version of the application.
Command to Scale a Kubernetes Deployment
Scaling the deployment can be done in many ways we can do it by using the following command.
kubectl scale deployment/tomcat-1stdeployment --replicas= 5
You can do the scaling of the pods with the help of horizontal pod autoscaling by enabling it in the cluster where you chose the required no.of pods to run continuously if there is traffic or not and how many no.of pods should be run while the incoming traffic is increased.
kubectl autoscale deployment/tomcat-1st deployment --min=5 --max=8 --cpu-percent=75
–min= 5 defines how many minimum no.of pods are to be run if there is traffic or not and if there is sudden traffic –max= 8 to how much it can maximize it and it depends upon the –CPU-percent.
Pausing and Resuming a rollout of a Kubernetes Deployment
You can pause the deployments which you are updating currently and resume the fallout updates for deployment when you feel that the changes are made correctly you can use the following command to pause the rollouts.
kubectl rollout pause deployment/webapp-deployment
To resume the deployment which is paused you can use the following command.
kubectl rollout resume deployment/webapp-deployment
When you pause the rollouts you can update the image by using the following command. Then the current version of the deployment will be replaced with the image which we are going to update.
kubectl set image deployment/webapp-deployment webapp=webapp: 2.1
Kubernetes Deployment Status
The deployment will pass different stages while it was in deploying. Each stage will say the health of the pods and shows us if any problems are arising.
There are a few deployment statuses as follows which will show the health of the pods there are.
- Pending: Deployment is pending representing that it going to start or it is facing some issues to start.
- Progressing: Deployment was in progress it was going to be deployed.
- Succeeded: Deployment was deployed successfully without any errors or bugs.
- Failed: Deployment was not deployed successfully it failed due to some issues.
- Unknown: This happens if the kubernetes API is not reached for deployment or the problem with the deployment itself.
Deployment status will help you to monitor the pods and you can take action immediately if you found any trouble or bugs in it.
Progressing Kubernetes Deployment
If any deployment is in progress it is meant to be that deployment is in the stage of updating or creating a new replicaset. Following are some of the reasons that deployment is in progress.
- The deployment is creating for the first time or it was creating a new replicaset.
- If the deployment is going under the updation or scaling then it will be in progress.
- The deployment will be in progress when the pods are scaling down or the pod is getting started.
If you want to troubleshoot the deployment then you can use the following command.
kubectl describe deployments
Complete Kubernetes Deployment
The following conditions must be satisfied to mark deployment as completed.
- All the replicas of the pods must be up and running.
- The desired count of pods must match the running count of pods.
- All the replicas of the pods which are associated with the deployment must be available.
- There must be no single replica of old pods must be running.
To check the status of the pods which are running you can use the following command.
kubectl rollout status <deployment/name of deployment>
Failed Kubernetes Deployment
Deployment may fail for several reasons when you try to deploy its newest ReplicaSet it may be in an incomplete position forever. This can cause for different reasons following are the reasons.
- There is a failure of the readiness probe and liveness probe.
- Error while pulling the image (Mentioned the wrong tag).
- There may be insufficient quota while deploying as we mentioned resources.
- The deployment cannot connect to a dependency, such as a database.
To get more information about the deployment and why is was failed you can use the following command. Which gives you a detailed description of the deployment.
kubectl describe deployments
Kubernetes Canary Deployment
The canary deployment will make sure that the deployment is going to content fifty percent of replicas are updated and fifty percent of replicas are older versions the replicas which are updated will be available for some of the end users and based upon their reviews we can replace all the replicas. If the reviews are positive you can update the remaining replicas if the feedbacks are bad then you can roll back to the previous version immediately.
The following are the two approaches to implementing canary deployment.
- Splitting the traffic using Istio.
- Blue/Green Deployment.
Use Cases of Kubernetes Deployments
Rollout a ReplicaSet: A Kubernetes deployment generates a replica set a pod that contains information regarding the number of pos to be generated in the background.
Declaring a New State of Pods: On updating pod template spec a new replica set is created and deployment moves pods from the old replica set to the new replica set.
Scaling: Deployment can be configured to scale up to facilitate more load.
Status of Deployment: It can be used to check if the deployment is stuck somewhere by matching the current status with the desired status.
Cleaning up old Replica Sets that are no more required.
ReplicaSets vs Deployments
| Feature / Aspect | ReplicaSet | Deployment |
|---|---|---|
| Purpose | Ensures a specified number of identical pod replicas are running at any given time. | Provides declarative updates for Pods and ReplicaSets — manages the full lifecycle of applications (create, update, rollback). |
| Abstraction Level | Low-level controller that directly manages Pods. | Higher-level abstraction built on top of ReplicaSets. |
| Pod Management | Only maintains the desired number of replicas; cannot perform rolling updates or rollbacks. | Manages ReplicaSets internally, handles rolling updates, rollbacks, and versioning automatically. |
| Use Case | Used when you only need to ensure pod replication without frequent updates or version management. | Used for production workloads where you need easy updates, rollbacks, scaling, and controlled rollout strategies. |
| Update Strategy | Doesn’t support update strategies; manual intervention is needed to update pods. | Supports rolling updates and rollback to previous revisions automatically. |
| Version Control | No versioning or history tracking. | Maintains revision history for every rollout (can check using kubectl rollout history). |
| Rollback Capability | Not supported — must delete and recreate pods manually if something goes wrong. | Fully supported using kubectl rollout undo deployment <deployment_name>. |
| Scaling | Supports manual scaling using kubectl scale replicaset. | Supports manual and declarative scaling using kubectl scale deployment or by updating YAML spec. |
| YAML Definition | Has its own YAML definition but is rarely used directly in real-world scenarios. | The YAML definition includes ReplicaSet and Pod templates internally — preferred by DevOps teams. |
| Self-Healing | Yes, if a pod dies, it recreates it. | Yes, via underlying ReplicaSet; also ensures consistent rollout during update failures. |
| Example Command | kubectl create replicaset nginx-rs --image=nginx --replicas=3 | kubectl create deployment nginx-deploy --image=nginx --replicas=3 |
| Practical Usage | Rarely used directly — mostly used by Deployments or other controllers like DaemonSets. | Commonly used in CI/CD pipelines for managing production workloads. |
| Interview Tip | ReplicaSet ensures availability. | Deployment ensures availability + version control + automated rollout/rollback. |
Some interview questions
1. How would you perform a rolling update on a Deployment without downtime?
Scenario: You have a live web application running in production, and you need to update the image version.
Answer:
Use kubectl set image deployment/<deployment_name> <container_name>=<new_image>:<tag>.
Deployments automatically create a new ReplicaSet with the updated pods and gradually scale it up while scaling down the old one.
Ensure maxUnavailable and maxSurge values in strategy.rollingUpdate are set correctly to avoid downtime.
Check rollout status using kubectl rollout status deployment/<deployment_name>.
2. How can you rollback a Deployment if the new version causes issues?
Scenario: After a rolling update, users report bugs.
Answer:
Use kubectl rollout undo deployment/<deployment_name> to revert to the previous version.
You can also rollback to a specific revision with --to-revision=<revision_number>.
Verify the rollback with kubectl rollout status and check pod versions using kubectl get pods.
3. What happens if a pod in a Deployment fails during a rolling update?
Scenario: During an update, one pod fails to start.
Answer:
Kubernetes halts the rollout and does not scale up new pods beyond the maxUnavailable limit.
The Deployment automatically retries creating new pods until the rollout is successful.
This ensures zero downtime and consistency.
You can check details with kubectl describe deployment <name> and kubectl get events.
4. How would you scale a Deployment manually and automatically?
Scenario: Traffic spikes for your app; you need to scale pods.
Answer:
Manual Scaling: kubectl scale deployment <deployment_name> --replicas=<number>
Auto-Scaling: Use Horizontal Pod Autoscaler (HPA): kubectl autoscale deployment <deployment_name> --min=2 --max=10 --cpu-percent=50
Deployment ensures underlying ReplicaSets are updated to reflect scaling.
5. How does Deployment ensure high availability during updates?
Scenario: Updating pods for a production app with 3 replicas.
Answer:
Deployment’s rollingUpdate strategy controls maxUnavailable and maxSurge.
New pods are gradually created before old pods are terminated.
At least the number of available pods specified in replicas is maintained throughout the update.
6. Can you update environment variables or config in a Deployment without downtime?
Scenario: You need to update API keys or configuration in pods.
Answer:
Update env section in the Deployment YAML or ConfigMap.
Apply the changes using kubectl apply -f <deployment_yaml>
Deployment creates new pods with updated configuration and deletes old pods gradually.
This ensures continuous service availability.
7. How can you check the rollout history and revisions of a Deployment?
Scenario: You want to know all previous updates and versions applied.
Answer:
Use kubectl rollout history deployment <deployment_name> to see revisions.
Detailed info of a specific revision: kubectl rollout history deployment <deployment_name> --revision=2
Useful for auditing and rollback purposes.
8. What strategy would you use for zero-downtime deployment with risky changes?
Scenario: A critical change might break the app if all pods update at once.
Answer:
Use RollingUpdate strategy with maxUnavailable: 1 and maxSurge: 1 for minimal impact.
Optionally, deploy to a separate namespace or staging cluster first for testing.
Monitor pods and application logs during rollout.
9. How do Deployments interact with ReplicaSets internally?
Scenario: Understanding the architecture behind Deployment updates.
Answer:
Deployment manages ReplicaSets, not Pods directly.
Each new version of a Deployment creates a new ReplicaSet.
Old ReplicaSets remain until they are scaled down or deleted.
This allows rollback and version control of applications automatically.
10. How would you handle a situation where some pods remain in Pending state after deployment?
Scenario: Pods don’t start after deployment.
Answer:
Check events using kubectl describe pod <pod_name> for scheduling issues.
Possible causes: insufficient resources, node taints, or missing PersistentVolumeClaims.
Deployment doesn’t consider Pending pods as “ready,” so rollout may be incomplete.
Resolve resource issues and monitor until pods are Running and READY.
Conclusion
Kubernetes Deployments are a fundamental building block for managing application lifecycles in a cluster. They provide a declarative approach to define the desired state of applications, ensuring that the required number of pods are always running and healthy. Deployments simplify critical operations such as scaling, rolling updates, rollbacks, and canary deployments, enabling teams to deliver new features or fixes with minimal downtime and risk.
By leveraging Deployments, DevOps engineers can maintain high availability, version control, and automated self-healing through underlying ReplicaSets. Understanding the full spectrum of Deployment operations—from creating and updating pods, monitoring rollout status, handling failures, to scaling with demand—is essential for both managing production workloads effectively and performing well in Kubernetes-focused interviews.
