
Autoscaling in Kubernetes is the process of automatically adjusting computing resources in a cluster based on workload demand. It can scale pods, nodes, or resources up and down to ensure applications remain available, efficient, and cost-effective.
There are three different methods of Kubernetes autoscaling:
Horizontal Pod Autoscaler (HPA)
Vertical Pod Autoscaler (VPA)
Cluster Autoscaler (CA)
1. Kubernetes Horizontal Pod Autoscaling(HPA)
Horizontal Pod Autoscaler (HPA) is a Kubernetes controller that automatically scales pods.
- It increases or decreases the number of pod replicas based on application workload.
- Scaling is triggered when preconfigured thresholds are reached.
- In most applications, scaling is mainly based on CPU usage.
- To use HPA, you must define the minimum number of pods and the maximum number of pods.
- You need to set the target CPU or memory usage percentage.
- Once configured, Kubernetes continuously monitors pods and automatically scales them within the defined limits.
Example: In apps like Airbnb, traffic spikes during offers. HPA adds pods automatically when CPU usage crosses the set limit, preventing slowdowns or downtime.
YAML code for HPA
apiVersion: autoscaling/v2
#this specifies Kubernetes API Version
kind: HorizontalPodAutoscaler
# this specifies Kubernetes object like HPA or VPA
metadata:
name: name_of_app
spec:
scaleTargetRef:
apiVersion: apps/v2
kind: Deployment
name: name_of_app
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 40
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 40
targetCPUUtilizationPercentage sets the CPU usage target for HPA.
In this example, it is set to 50%.
HPA scales the deployment automatically between 1 and 10 replicas.
If CPU usage exceeds 50%, HPA scales up to maintain optimal performance.
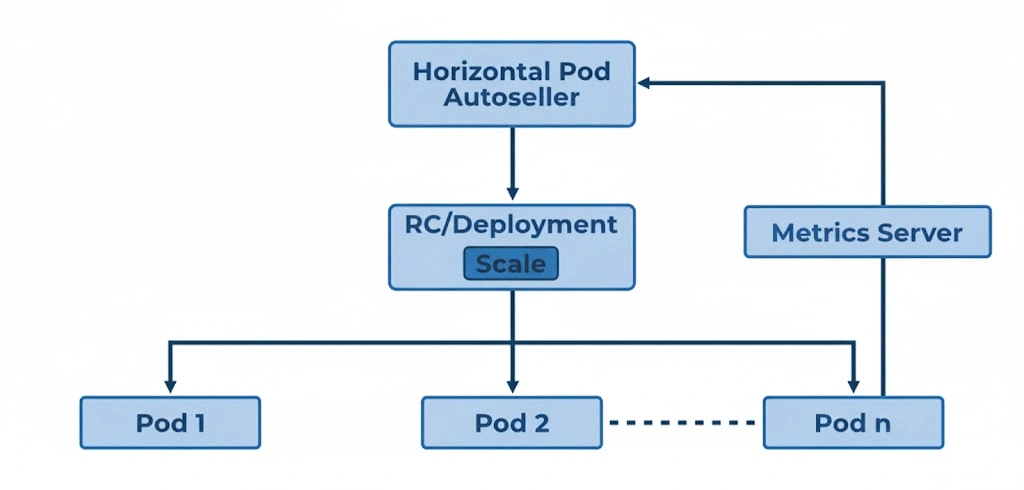
Working of Horizontal Pod Autoscaler
The Horizontal Pod Autoscaler (HPA) dynamically adjusts the number of Pods in a deployment based on real-time resource usage. It follows a continuous and adaptive cycle that includes the following key steps:
1. Metrics Collection:
First, the HPA continuously monitors resource usage—such as CPU and memory—across all Pods. The Kubernetes Metrics Server actively gathers this data at regular intervals (typically every 15 seconds) and then shares it with the HPA for further evaluation. Consequently, the system always operates on the latest performance data.
2. Threshold Comparison:
Next, the HPA compares the observed resource usage with the desired threshold. For instance, if the CPU utilization target is 60%, and the actual usage exceeds that limit, Kubernetes immediately recognizes that the workload demands additional resources. Therefore, the system prepares to scale the number of Pods accordingly.
3. Scaling Logic:
After the comparison, the HPA decides whether to increase or decrease the number of Pods. If CPU usage rises above the threshold (for example, 70%), it quickly adds more Pods to balance the load. Conversely, if usage falls significantly (say 30%), the HPA reduces the Pod count to optimize resource utilization. This proactive scaling ensures both performance and cost-efficiency.
4. Feedback Loop:
Finally, the HPA operates within a continuous feedback loop. As application traffic and resource demands fluctuate, it repeatedly gathers metrics, evaluates thresholds, and adjusts the Pod count in real time. Consequently, the system remains responsive and maintains consistent application performance under varying workloads.
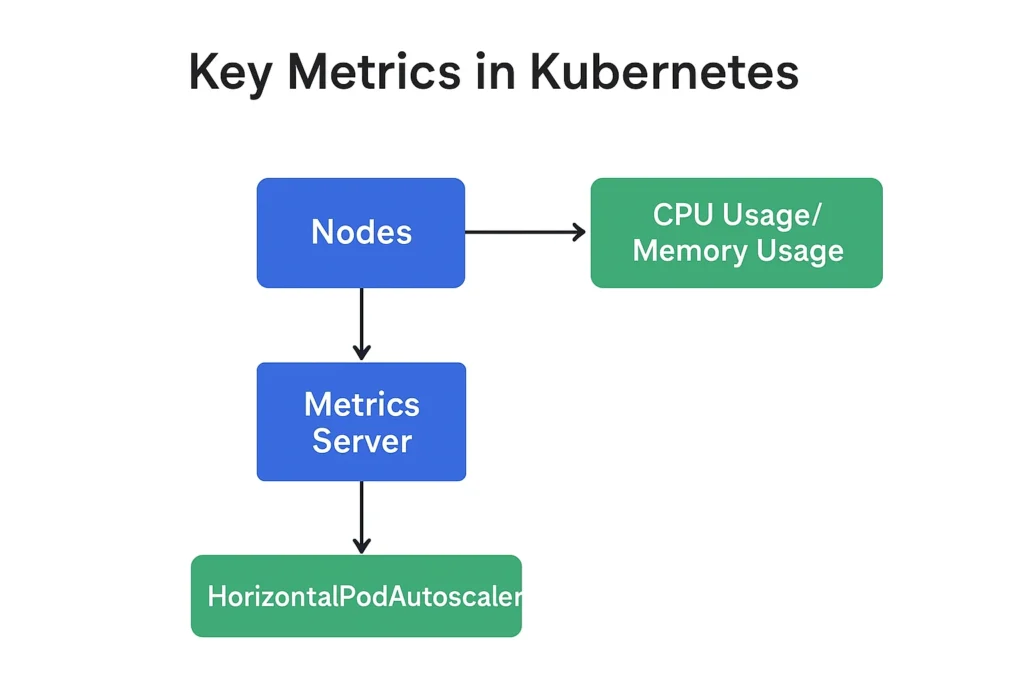
Key Metrics
- CPU Usage:
- Measured in millicores (m): 1000m = 1 CPU core.
- Usage: The amount of CPU time the the container consumes.
- Limit: The maximum amount of CPU resources that may be utilized by the container.
- Request: The smallest amount of CPU resources that the container gets is guaranteed.
- Memory Usage:
- Measured in bytes (B), kilobytes (Ki), megabytes (Mi), etc..
- Usage: The amount of RAM which the container utilizes at this point in time.
- Limit: The greatest quantity of RAM that is permitted to used by the container.
- Request: The smallest amount of memory that the container will always possess.
Resource Requests and Limits: You may set resource requests and limitations when defining a container in a pod specification in order to make sure the container gets the resources that it needs and to prevent it from using more than it should. This improves the cluster’s capacity to distribute assets and provide high-quality services.
Collecting Metrics: The Kubernetes Metrics Server is a cluster-wide consumption of resources data aggregator which can be utilized for collecting metrics. It collects metrics from each node’s Kubelet and then makes them accessible through the Kubernetes API.
Using Metrics for Autoscaling: These metrics are employed by the HorizontalPodAutoscaler (HPA) to automatically adjust the number of pod replicas based to observed utilization of resources.
Viewing Metrics: The Kubernetes Dashboard or the kubectl top commands may be employed to view metrics.
- View Node Metrics:
kubectl top nodes
2. View Pod Metrics: kubectl top pods
How to Use Kubernetes Horizontal Pod Autoscaler?
The process of automatically scaling in and scaling out of resources is called Autoscaling. There are three different types of autoscalers in Kubernetes: cluster autoscalers, horizontal pod autoscalers, and vertical pod autoscalers. In this article, we’re going to see Horizontal Pod Autoscaler.
Application running workload can be scaled manually by changing the replicas field in the workload manifest file. Although manual scaling is okay for times when you can anticipate load spikes in advance or when the load changes gradually over long periods of time, requiring manual intervention to handle sudden, unpredictable traffic increases isn’t ideal.
To solve this problem, Kubernetes has a resource called Horizontal Pod Autoscaler that can monitor pods and scale them automatically as soon as it detects an increase in CPU or memory usage (Based on a defined metric). Horizontal Pod Autoscaling is the process of automatically scaling the number of pod replicas managed by a controller based on the usage of the defined metric, which is managed by the Horizontal Pod Autoscaler Kubernetes resource to match the demand.
Step By Step Setup
1. Create a Kind Cluster (if not already created)
cat <<EOF | kind create cluster --name kind-hpa --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
EOF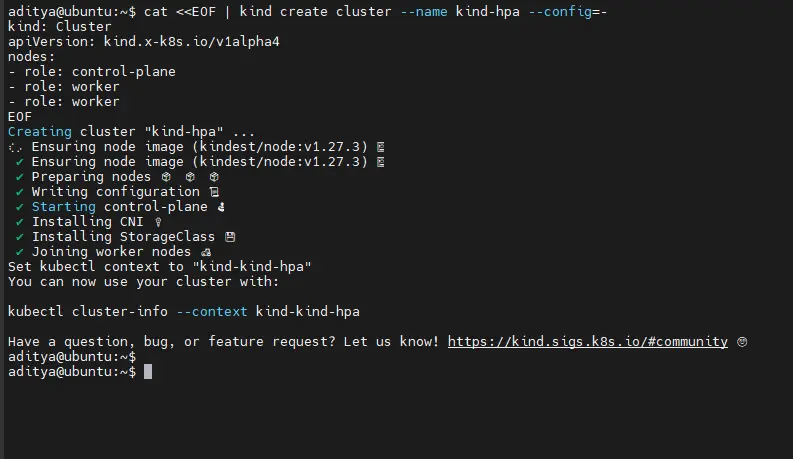
Verify nodes:
kubectl get nodes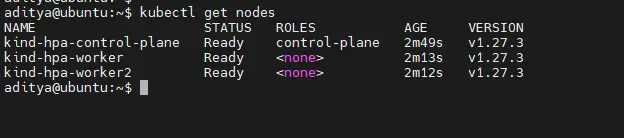
2. Deploy Metrics Server (Kind-compatible)
Metrics-server needs insecure TLS flags on Kind. Use this command to apply the fixed deployment:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
Then patch it to work with Kind:
kubectl patch deployment metrics-server -n kube-system \
-p '{
"spec": {
"template": {
"spec": {
"containers": [
{
"name": "metrics-server",
"args": [
"--cert-dir=/tmp",
"--secure-port=10250",
"--kubelet-preferred-address-types=InternalIP",
"--kubelet-insecure-tls",
"--kubelet-use-node-status-port",
"--metric-resolution=15s"
]
}
]
}
}
}
}'Restart the metrics-server pod:
kubectl rollout status deployment metrics-server -n kube-systemCheck the pod status:
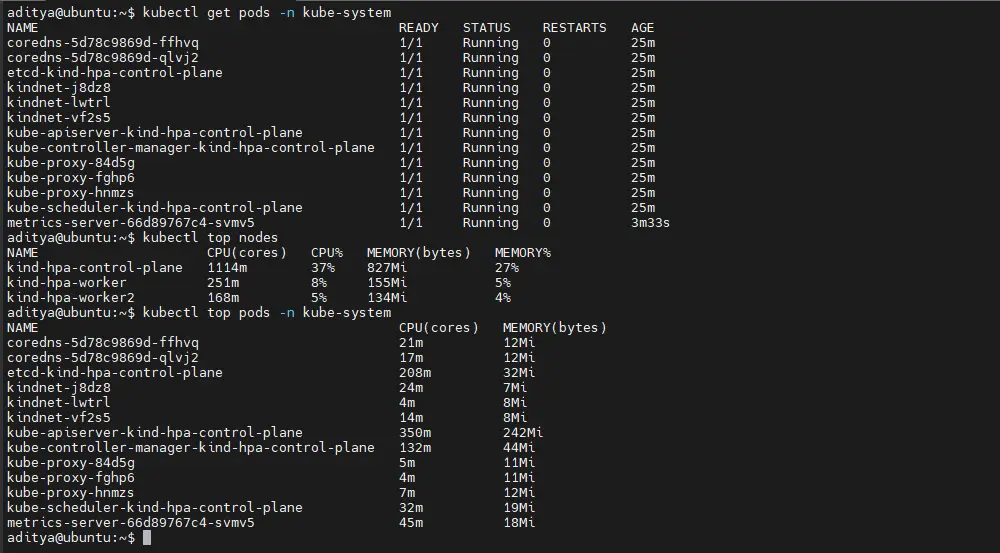
kubectl get pods -n kube-system
kubectl top nodes
kubectl top pods -n kube-system If kubectl top shows CPU/memory, metrics-server is working.
3. Deploy a Sample Application
Create a deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
type: ClusterIP
ports:
- protocol: TCP
port: 80
targetPort: 80
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-deployment
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 104. Create Horizontal Pod Autoscaler
Scale based on CPU usage:
kubectl autoscale deployment nginx --cpu-percent=50 --min=1 --max=5
kubectl get hpa
5. Generate Load to Trigger HPA
Run a temporary pod to generate CPU load:
kubectl run -i --tty load-generator --image=busybox /bin/shInside the pod, run:
while true; do wget -q -O- http://nginx-service; done
6. Monitor HPA Scaling
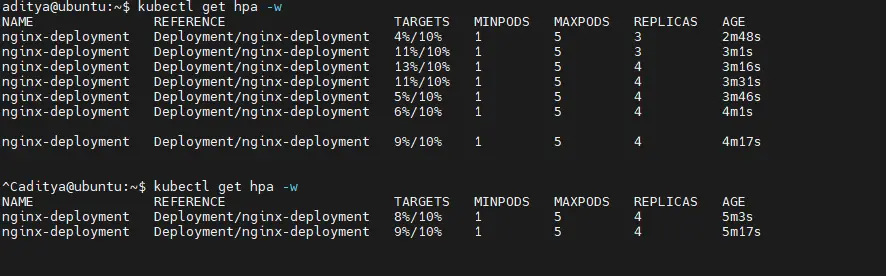
Check autoscaling in action:
kubectl get hpa -w
kubectl get pods -o wideYou should see replicas increase as CPU usage rises.
Once load drops, HPA scales down to the minimum replicas.
Limitations of HPA
The HorizontalPodAutoscaler (HPA) is great for scaling applications automatically in Kubernetes but it does have limitations that can impact its use in real-world scenarios:
- Limited Metric Support: HPA mainly uses CPU and memory for scaling which may not represent the true load. Applications often need to scale based on other factors like request rates or network traffic. Custom metrics can be added but this requires extra setup and complexity.
- Reactive Scaling: HPA reacts after thresholds are breached rather than scaling proactively. This can leave your application under-provisioned during sudden traffic spikes causing poor performance. You can use predictive scaling models but that adds complexity to infrastructure.
- One Metric at a Time: HPA typically scales based on one metric like CPU or memory. Many applications need multiple factors like network or request rate considered together. To handle this you can use tools like KEDA but it increases operational overhead.
- Handling Burst Traffic: HPA struggles with burst traffic since it does not scale fast enough to handle sudden demand spikes. Using queue-based systems like RabbitMQ can help manage bursts but adds more complexity.
- Scaling Granularity: HPA scales pods as whole units which may be inefficient for applications that need finer control over resources like just increasing CPU. For more precise scaling the VerticalPodAutoscaler (VPA) can adjust resources for individual pods.
- Fixed Scaling Intervals: HPA checks metrics at fixed intervals which can miss short traffic spikes. This can lead to delayed scaling or inefficient resource usage in dynamic environments. Adjusting the interval or combining HPA with event-driven scaling can help.
For a practical implementation guide on how to set up the Autoscaling nn Amazon EKS, refer to – Implementing Autoscaling in Amazon EKS
Usage and Cost Reporting with HPA
The Horizontal Pod Autoscaler (HPA) in Kubernetes helps keep applications performing optimally by adjusting the number of pod replicas based on demand to avoid over-provisioning and reduce costs. This guide explains how to monitor and report on HPA-driven usage to manage costs effectively.
Tracking HPA’s impact on costs helps avoid unnecessary expenses while capturing usage patterns to refine scaling decisions based on real data.
Setting Up Usage and Cost Reporting with HPA
- Define Metrics and Cost Allocation to track CPU memory and scaling events with tags for accurate cost attribution
- Use Monitoring Tools like Prometheus and Grafana to visualize usage patterns and compare metrics to cost data
- Add Custom Metrics to tailor HPA for specific application needs to keep scaling efficient
Support for HorizontalPodAutoscaler in kubectl
The HorizontalPodAutoscaler (HPA) in Kubernetes handles scheduling pod scaling up automatically based on resource use metrics as CPU or memory. Below is an overview of how it operates:
Create Autoscaler: Kubectl create can be utilized to construct a new HPA in the exact same way that any other resource. This option enables a fast and efficient autoscaler setup.
List HPAs: Use kubectl get hpa to get all of your current HPAs. Using the assistance of this command, you are able to view the names, target resources, and scaling environments of all of your current autoscalers.
Describe HPA: Use kubectl describe hpa to secure additional information about a specific HPA. Full details about the autoscaler, including events, metrics, and scaling history, is given by this command.
Specialized Autoscale Command: In addition, kubectl autoscale, a specialized command created specifically for HPA development, is offered by Kubernetes. This command lets you specify scaling parameters directly, and streamlines the procedure. For example, kubectl autoscale deployment my-app –min=2 –max=5 –cpu-percent=80 creates an autoscaler with a replica count of between two and five and a target CPU utilization of 80% for the my-app deployment.
Delete Autoscaler: Finally, you may execute kubectl delete hpa to eliminate an autoscaler following you finish using it. By deleting the assigned HPA from your cluster, this procedure guarantees efficient resource management.
Advantages Using HPA
Monitoring Resource Usage in Kubernetes
Monitoring resource usage in Kubernetes is essential for maintaining application performance and ensuring cluster stability. Proper resource management prevents bottlenecks and enables workloads to run efficiently, keeping the cluster healthy under varying demands.
CPU Metrics
CPU usage in Kubernetes is measured in millicores (m), where 1000m equals one full CPU core. It reflects the amount of processing time a container consumes. The CPU request specifies the minimum CPU guaranteed for a container, while the CPU limit defines the maximum it can use. By setting these values, administrators ensure fair distribution of processing power among containers and prevent any single container from monopolizing CPU resources.
Memory Metrics
Memory usage shows the RAM currently consumed by a container. The memory request guarantees a minimum allocation, and the memory limit sets an upper boundary. Properly configuring these values helps avoid memory contention and potential out-of-memory (OOM) errors, maintaining application stability under varying load conditions.
Resource Requests and Limits
Defining requests and limits in a Pod specification allows Kubernetes to allocate resources fairly across containers. This practice prevents resource contention, enhances cluster efficiency, and ensures that workloads operate smoothly without affecting each other.
Collecting Resource Metrics
Kubernetes relies on the Metrics Server to gather resource usage metrics. It collects data from each node’s Kubelet and exposes it through the Kubernetes API. These metrics are crucial for Horizontal Pod Autoscaling (HPA), which adjusts the number of Pod replicas automatically based on real-time CPU or memory consumption.
Viewing Metrics
Administrators can monitor cluster resource usage using the Kubernetes Dashboard, which offers a visual representation of metrics. Alternatively, they can use kubectl commands, such as kubectl top nodes for node-level metrics and kubectl top pods for Pod-level metrics. Together, these tools provide actionable insights into cluster performance and help maintain smooth operations.
Benefits of Horizontal Pod Autoscaling (HPA)
Horizontal Pod Autoscaling improves Kubernetes workload management by automatically scaling Pod replicas according to current resource demands. This ensures applications remain responsive during traffic spikes while avoiding over-provisioning during low usage. Dynamic scaling optimizes resource utilization, enhances system reliability, and reduces infrastructure costs. Furthermore, HPA supports high availability by maintaining sufficient replicas to handle workloads, ensuring consistent service delivery even under unpredictable load conditions. Overall, it enables organizations to operate applications efficiently, maintain performance, and manage resources effectively.
Conclusion
Horizontal Pod Autoscaling (HPA) is a powerful feature in Kubernetes that enables applications to automatically scale in response to real-time resource demands. By monitoring CPU and memory usage through the Metrics Server, HPA ensures optimal resource utilization, maintains application performance, and enhances cluster reliability. It reduces manual intervention, prevents over- or under-provisioning, and supports high availability during traffic fluctuations. Implementing HPA allows organizations to run workloads efficiently, improve responsiveness, and achieve cost-effective scaling, making it an essential tool for managing dynamic workloads in Kubernetes environments.
