
Kubernetes scheduling is responsible for assigning pods (groups of one or more containers) to nodes in a cluster. The scheduler’s primary objective is to optimize resource utilization and ensure that the application runs smoothly and efficiently. It takes into account factors such as hardware capabilities, available resources, quality of service (QoS), and affinity settings.
Efficient scheduling is crucial for maximizing resource utilization, improving application performance, and ensuring high availability in a Kubernetes cluster. By intelligently assigning pods (groups of containers) to nodes (individual machines in the cluster), Kubernetes scheduling enables workload distribution, load balancing, and fault tolerance. It plays a vital role in optimizing resource allocation, minimizing bottlenecks, and providing a seamless user experience.
How Kubernetes Scheduling Works
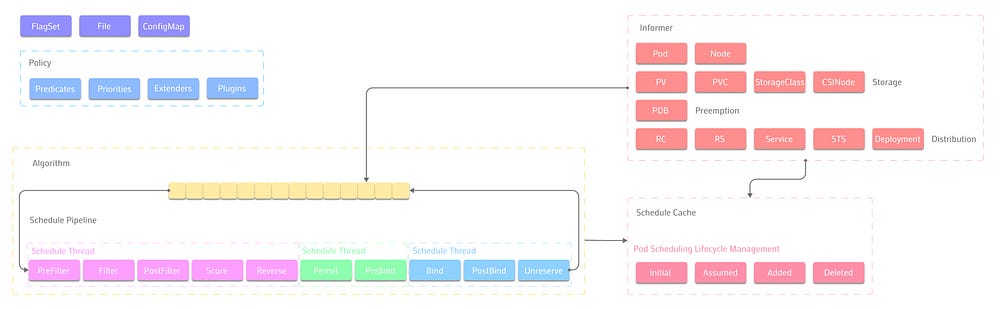
Kubernetes scheduling has two main phases: filtering and scoring. In the filtering phase, the scheduler eliminates nodes that cannot run a pod. For example, if a pod requests 2 GB of memory, the scheduler removes nodes with less than 2 GB of free memory. During the scoring phase, the scheduler assigns a score to each remaining node based on factors such as resource utilization, pod affinity, and node affinity. The scheduler then selects the node with the highest score as the best fit for the pod.
The scheduler implements these phases using predicates and priorities. Predicates are boolean functions that return true or false for each node. They handle the filtering logic. Priorities are numeric functions that return a score between 0 and 10 for each node. They handle the scoring logic.
Kubernetes includes a default set of predicates and priorities to cover common scheduling scenarios:

You can also define custom predicates and priorities by using the scheduler extender mechanism or writing a custom scheduler plugin. This allows you to fine-tune scheduling decisions to meet specific workloads or business requirements.
Understanding the Scheduling Algorithm
A)Node Selection
The first step in the Kubernetes scheduling algorithm is node selection. When a new pod is created, the scheduler evaluates the available nodes in the cluster and identifies suitable candidates for hosting the pod.
This evaluation is based on several factors, including:
1.Taints and tolerations
Mechanisms used in Kubernetes to manage pod placement and eviction decisions based on node conditions. A taint represents a condition on a node that makes it unsuitable for running certain pods, such as a lack of available resources or a software component failure. A toleration allows a pod to specify that it can tolerate certain taints on a node, enabling it to still run even if the node has limited resources or other issues. By using taints and tolerations, administrators can ensure that critical workloads receive priority access to suitable nodes while less sensitive workloads can still run on nodes with known limitations
2.Resource availability
Ability of a computing system to allocate resources such as CPU, memory, storage, and network bandwidth to meet the demands of its workloads. It involves ensuring that there are sufficient resources available to run applications and services without bottlenecks or interruptions. Resource availability can be managed through techniques like resource scheduling, load balancing, and auto-scaling
3.Node capacity
maximum amount of resources that a single node in a distributed system can handle. It includes factors such as processing power, memory size, storage capacity, and network interface capabilities. Understanding node capacity is important for scaling applications horizontally (adding more nodes) and vertically (increasing resources on individual nodes)
4.Affinity
Tendency of certain tasks or processes to co-locate or run together on the same node or set of nodes in a distributed system. This can be due to factors such as shared data access patterns, communication overhead, or performance optimization. Affinity can be used to improve application performance by minimizing network latency and maximizing resource utilization
6.Anti-affinity rules
Used to prevent certain tasks or processes from running together on the same node or set of nodes in a distributed system. These rules are typically used when two or more processes have conflicting resource requirements or need to maintain isolation for security or compliance reasons. For example, anti-affinity rules may be used to ensure that multiple instances of a mission-critical application do not run on the same node to avoid overloading it
B)Scoring and Prioritization
Once the candidate nodes are identified, the scheduler assigns a score to each node based on a set of predefined criteria.
These criteria include factors:
1. Resource utilization
Allocation and usage of computing resources such as CPU, memory, storage, and network bandwidth within a cluster. It is important to monitor and manage resource utilization to ensure that nodes have sufficient resources available to run applications efficiently and avoid overprovisioning or underutilization
node capacity: the maximum amount of resources that a node can provide to run applications. It includes factors such as the number of CPU cores, memory size, and storage capacity
2.Pod affinity and anti-affinity:
Ability of Kubernetes to schedule pods together on the same node or separate them across different nodes based on their relationships. Affinity rules define how pods should be placed relative to each other, such as co-locating dependent pods or separating them for fault tolerance. Anti-affinity rules specify which pods should never be scheduled on the same node. Managing pod affinity and anti-affinity ensures efficient use of resources and minimizes application downtime
3. Inter-pod communication requirements
Exchange of data between two or more pods in a cluster. Understanding communication requirements is essential to configure networking policies, choose appropriate service discovery mechanisms, and optimize performance. Communication patterns can vary from simple HTTP requests to complex distributed tracing and service mesh architectures
4.User-defined constraints
Custom limitations or restrictions that users can set on their deployments, services, or pods. These constraints can include parameters such as minimum or maximum instances, CPU or memory limits, or specific hardware requirements. By defining constraints, users can ensure that their applications operate within desired boundaries, preventing overprovisioning or overspending, and maintaining compliance with organizational policies or regulatory requirements
The scheduler then prioritizes the nodes based on their scores, with higher-scoring nodes given preference for hosting the pod.
Resource Allocation and Bin Packing
After prioritization, the scheduler performs resource allocation and bin packing to determine the optimal placement of pods on nodes.
It takes into account the resource requirements of the pods, such as CPU and memory, and ensures that the nodes have sufficient capacity to accommodate the pods.
The scheduler aims to maximize resource utilization and avoid overloading nodes, while also considering any user-defined constraints or preferences.
Pod Binding and Affinity Rules
Once a suitable node is identified for a pod, the scheduler binds the pod to that node, marking it as scheduled.
The scheduler also considers pod affinity and anti-affinity rules, which allow users to specify constraints on the placement of pods.
Affinity rules can be used to ensure that pods are co-located on the same node or spread across different nodes, based on specific requirements or dependencies.
Customizing the Scheduling Process
Node Selectors
Node selectors allow users to specify a set of key-value pairs that must match the labels assigned to nodes. By setting node selectors for pods, users can ensure that pods are scheduled only on nodes that meet specific criteria, such as hardware capabilities or geographical location.
Node Affinity and Anti-Affinity
Node affinity and anti-affinity rules provide more fine-grained control over the placement of pods on nodes. Users can define rules that specify preferences or constraints for pod placement based on node labels, such as preferring nodes with SSD storage or avoiding nodes with specific labels.
Pod Affinity and Anti-Affinity
Similar to node affinity and anti-affinity, pod affinity and anti-affinity rules allow users to define preferences and constraints for pod placement based on pod labels. These rules can be used, for example, to ensure that pods are co-located on the same node for efficient inter-pod communication or to spread pods across different failure domains for improved fault tolerance.
Resource Quotas
Resource quotas enable users to limit the amount of resources that can be consumed by pods in a namespace. By setting resource quotas, administrators can prevent overutilization of resources and ensure fair allocation of resources across different workloads.
Custom Schedulers
Kubernetes also allows users to develop and deploy custom schedulers, which implement their own scheduling logic and policies. Custom schedulers can be used to incorporate domain-specific knowledge or to address unique scheduling requirements that are not covered by the default scheduler.
Scheduling Algorithms
Random
The random scheduling algorithm, also known as the “dumb” scheduler, selects a random node to run a pod on.
This algorithm is simple but not very efficient, as it doesn’t take into account factors such as resource utilization, hardware capabilities, or network latency.
It is rarely used in production environments, but can be useful for testing purposes or when there are no specific requirements for pod placement.
Least Requested
The least requested scheduling algorithm assigns pods to nodes with the fewest number of requests.
Each node maintains a count of the number of running pods, and the algorithm checks the count before scheduling a new pod. The node with the lowest request count is selected for scheduling.
This algorithm aims to distribute the load evenly among all nodes in the cluster. However, it may not always result in optimal resource utilization, especially if some nodes have more resources than others.
Most Requested
The most requested scheduling algorithm is the opposite of the least requested algorithm. It assigns pods to nodes with the highest number of requests.
This algorithm prioritizes nodes that are already running many pods, assuming that those nodes have sufficient resources available. While this algorithm can lead to better resource utilization, it can also create bottlenecks on popular nodes and lead to underutilization of other nodes.
Balanced Resource Allocation
The balanced resource allocation scheduling algorithm aims to allocate resources equally among all nodes in the cluster.
Before scheduling a new pod, the algorithm calculates the resource utilization ratio for each node, taking into account CPU, memory, and other relevant resources. The node with the lowest utilization ratio is selected for scheduling.
This algorithm ensures that no single node becomes overloaded, but it may not always optimize resource usage due to variations in resource requirements between pods.
Bin Packing
The bin packing scheduling algorithm is inspired by the classic bin packing problem in computer science.
It works by grouping pods into bins based on their resource requirements, then assigning bins to nodes. Each bin represents a set of pods that can fit within the resource constraints of a single node. The algorithm starts by creating an empty bin for each node, then iteratively adds pods to the bins until all pods are scheduled or there are no more available nodes.
This algorithm optimizes resource utilization by minimizing waste and maximizing the number of scheduled pods. However, it can be computationally expensive and may not handle changes in resource availability well.
Earliest Deadline First (EDF)
The earliest deadline first scheduling algorithm is a variant of the rate monotonic scheduling (RMS) algorithm.
It assigns priority to pods based on their deadlines, with earlier deadlines receiving higher priority. The algorithm schedules pods in order of their deadlines, starting from the earliest. If multiple pods have the same deadline, the algorithm uses a round-robin approach to select the next pod.
EDF helps ensure timely completion of critical tasks but may cause starvation for lower-priority pods.
Rate Monotonic Scheduling (RMS)
Rate monotonic scheduling is a family of scheduling algorithms that assign priority to pods based on their rates, which represent the amount of work that can be completed per unit time.
RMS algorithms aim to distribute the total rate of incoming requests among available nodes, ensuring predictable performance and fairness.
There are several variants of RMS, including EDF, least laxity first (LLF), and proportional sharing.
Hierarchical
Hierarchical scheduling combines multiple scheduling algorithms to create a hierarchical structure.
For example, a cluster-level scheduler might use a combination of random, least requested, and most requested algorithms to allocate pods across nodes, while a node-level scheduler employs a rate monotonic algorithm to schedule containers within each node.
This approach allows for greater flexibility and adaptability to various workloads.
Types of Scheduling Criteria
Required Resources
Required resources refer to the minimum amount of resources (CPU, memory, etc.) required by a pod to run successfully.
Kubernetes ensures that these resources are always available on the node hosting the pod.
Requested Resources
Requested resources refer to the maximum amount of resources a pod can request.
Kubernetes tries to allocate these resources but doesn’t guarantee them. If there aren’t enough resources available, the pod may still run, but it may not perform optimally.
Limits
Limits refer to the maximum amount of resources a pod can consume.
Kubernetes enforces these limits to prevent a single pod from consuming all the resources on a node and starving other pods.
Quality of Service (QoS)
Quality of Service (QoS) refers to the level of service a pod requires. QoS classes are used to group pods based on their resource requirements and priorities.
Kubernetes provides three QoS classes:
- Best Effort: default QoS class for pods that don’t require any special treatment. Pods in this class are scheduled based on the available resources and may be preempted if necessary
- Burstable: allows pods to temporarily exceed their requested resources during periods of high demand. Once the demand subsides, the pods must relinquish any excess resources to avoid being evicted
- Guaranteed: guarantees a pod will always have access to its requested resources. These pods are given top priority and cannot be preempted unless absolutely necessary
How Taints, Tolerations, Node Affinity, and Topology Spread Constraints Affect Scheduling
In Kubernetes, scheduling a pod isn’t just about available resources—it’s also about ensuring workloads run on the right nodes under the right conditions. Kubernetes provides mechanisms like taints, tolerations, node affinity, and topology spread constraints to influence scheduling decisions, giving cluster operators fine-grained control over where pods land.
Taints and Tolerations
Taints are applied to nodes to repel certain pods from being scheduled on them. Think of a taint as a “do not disturb” sign. For example, a node with high memory pressure or dedicated for special workloads might have a taint:
key=memory-pressure, effect=NoSchedulePods that don’t tolerate this taint won’t be scheduled on that node. To allow a pod to be scheduled despite a taint, you add a toleration to the pod. Tolerations “tolerate” the taint, allowing the pod to bypass the restriction. This mechanism ensures that nodes reserved for specific purposes don’t accidentally host unrelated workloads, keeping critical resources safe.
Node Affinity
Node affinity lets you express preferences or requirements about which nodes a pod should run on. It’s like giving the scheduler a “wish list.” There are two types:
- RequiredDuringSchedulingIgnoredDuringExecution: Hard rules that must be met for the pod to be scheduled. For instance, you might require a pod to run on nodes labeled
zone=us-east-1a. - PreferredDuringSchedulingIgnoredDuringExecution: Soft rules that are desirable but not mandatory. The scheduler will try to honor them but will place the pod elsewhere if necessary.
Node affinity allows workloads to be placed based on node labels, such as hardware type, geographic location, or custom attributes, improving performance, compliance, or cost optimization.
Topology Spread Constraints
Topology spread constraints help distribute pods evenly across your cluster, preventing hotspots and improving availability. You can define rules like “run no more than 50% of pods in the same zone” or “spread pods across nodes with different racks.”
This ensures that if a particular node, zone, or region fails, only a portion of your application is affected. Topology spread constraints are especially valuable for stateful applications or high-availability services, as they increase fault tolerance and resilience.
Putting It All Together
During scheduling, the Kubernetes scheduler evaluates each node based on these factors alongside resource availability and other scoring criteria:
- Taints and tolerations filter out nodes where pods are not allowed.
- Node affinity narrows down nodes based on required or preferred labels.
- Topology spread constraints guide the scheduler to distribute pods evenly across the cluster.
By combining these mechanisms, Kubernetes ensures pods run on suitable nodes while maintaining reliability, performance, and resource isolation. They empower operators to shape pod placement strategically rather than leaving it to chance.
Conclusion
Kubernetes scheduling is the backbone of efficient workload management in a cluster, intelligently placing pods on nodes to maximize resource utilization, ensure high availability, and maintain application performance. By leveraging mechanisms such as taints and tolerations, node affinity, and topology spread constraints, operators gain fine-grained control over pod placement, enabling strategic distribution of workloads, fault tolerance, and optimized inter-pod communication.
Understanding how the scheduler evaluates resources, affinities, and constraints not only helps in designing resilient applications but also ensures that clusters operate efficiently under varying workloads. With its combination of filtering, scoring, and sophisticated placement rules, Kubernetes scheduling transforms a cluster from a collection of nodes into a dynamic, self-optimizing system capable of running modern applications reliably and at scale.
