
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. Companies of all sizes and industries can use Amazon S3 to store and protect any amount of data for a range of use cases, such as data lakes, websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics. Amazon S3 provides management features so that you can optimize, organize, and configure access to your data to meet your specific business, organizational, and compliance requirements.
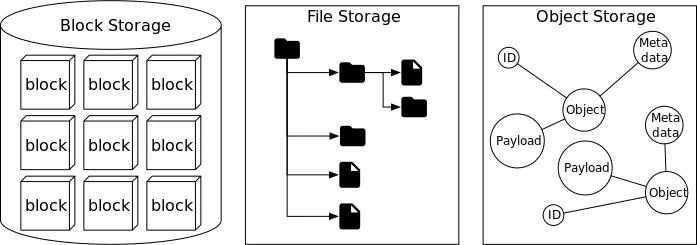
At a high level, storage systems fall into three broad categories:
- Block storage
- File storage
- Object storage
Block Storage
Block storage first appeared in the 1960s. Common devices such as hard disk drives (HDDs) and solid-state drives (SSDs) that attach directly to servers fall under this category.
In block storage, raw blocks are presented to the server as a volume. This makes it the most flexible and versatile storage type. The server can format the raw blocks into a file system or allow applications to control them directly. For example, databases and virtual machine engines often manage blocks on their own to maximize performance.
Block storage is not limited to local devices. Servers can also connect to it over high-speed networks using industry-standard protocols like Fibre Channel (FC) and iSCSI. Conceptually, the server still sees raw blocks, whether the storage is local or network-attached.
File Storage
File storage builds on top of block storage and provides a higher-level abstraction for managing data. Information is stored as files in a hierarchical directory structure, making it easy to handle.
This storage type is the most common general-purpose solution. Organizations can make it accessible to many servers using file-level protocols such as SMB/CIFS and NFS. In addition, servers using file storage do not need to manage raw blocks or formatting tasks. Because of its simplicity, file storage is ideal for sharing files and folders across teams.
Object Storage
Object storage is relatively new compared to block and file storage. It deliberately sacrifices performance in exchange for durability, scalability, and low cost. As a result, it is commonly used for backups and archiving “cold” data.
Instead of a directory hierarchy, object storage saves data as objects in a flat structure. Access is provided through RESTful APIs, which makes it slower than other storage types. However, its durability and scale make it perfect for large datasets. Popular examples include Amazon S3, Google Cloud Object Storage, and Azure Blob Storage.
How Amazon S3 works
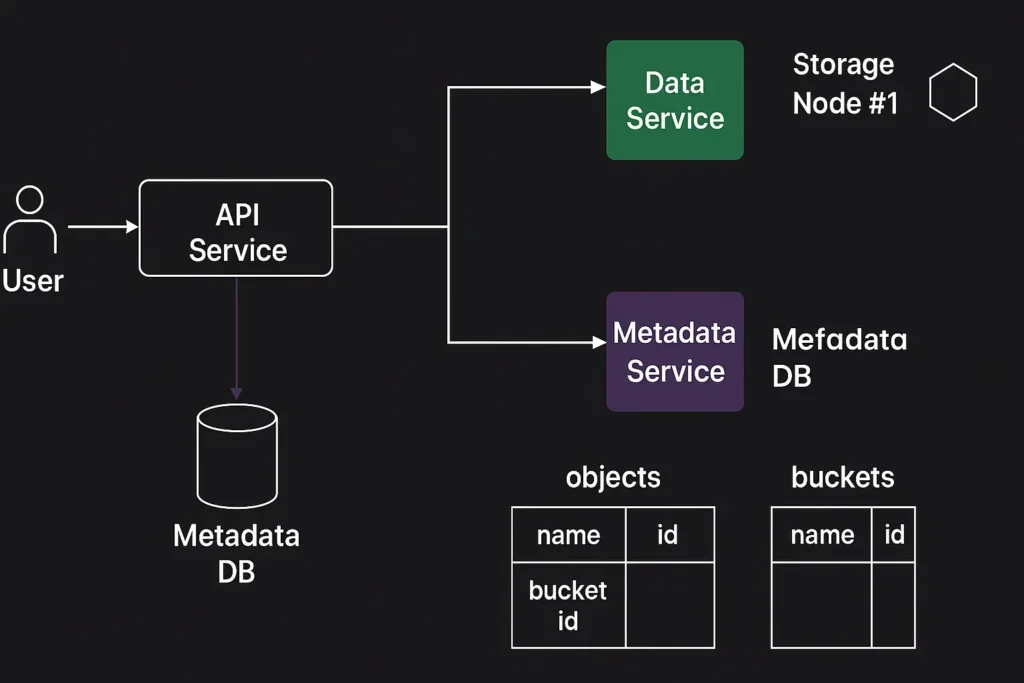
Amazon S3 is an object storage service that stores data as objects within buckets. An object is a file and any metadata that describes the file. A bucket is a container for objects.
To store your data in Amazon S3, you first create a bucket and specify a bucket name and AWS Region. Then, you upload your data to that bucket as objects in Amazon S3. Each object has a key (or key name), which is the unique identifier for the object within the bucket.
S3 provides features that you can configure to support your specific use case. For example, you can use S3 Versioning to keep multiple versions of an object in the same bucket, which allows you to restore objects that are accidentally deleted or overwritten.
Buckets and the objects in them are private and can be accessed only if you explicitly grant access permissions. You can use bucket policies, AWS Identity and Access Management (IAM) policies, access control lists (ACLs), and S3 Access Points to manage access.
To fully understand S3 we need to focus on two main topics:
- Buckets
- Objects
After this, we focus on understanding different strategies in S3 for managing these buckets and objects:
- Data Encryption
- Data Protection
- Optimizing Performance
S3 Buckets
To store your data in Amazon S3, you work with resources known as buckets and objects. A bucket is a container for objects. An object is a file and any metadata that describes that file.
Press enter or click to view image in full size.
To store an object in Amazon S3, you create a bucket and then upload the object to a bucket. When the object is in the bucket, you can open it, download it, and move it. When you no longer need an object or a bucket, you can clean up your resources.
AWS S3 supports three types of buckets that we will discuss in detail, these are: General-purpose buckets, Directory buckets, and Table buckets.
Amazon S3 supports global buckets, which means that each bucket name must be unique across all AWS accounts in all the AWS Regions within a partition. A partition is a grouping of Regions. AWS currently has three partitions: aws (Standard Regions), aws-cn (China Regions), and aws-us-gov (AWS GovCloud (US)).
Amazon S3 creates buckets in a Region that you specify. To reduce latency, minimize costs, or address regulatory requirements, choose any AWS Region that is geographically close to you. For example, if you reside in Europe, you might find it advantageous to create buckets in the Europe (Ireland) or Europe (Frankfurt) Regions.
Types of Amazon S3 Buckets
General Purpose Buckets
A general-purpose bucket is a container for objects stored in Amazon S3. You can store any number of objects in a bucket and all accounts have a default bucket quota of 10,000 general-purpose buckets.
Every object is contained in a bucket. For example, if the object named photos/puppy.jpg is stored in the amzn-s3-demo-bucket bucket in the US West (Oregon) Region, then it is addressable by using the URL https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg.
S3 General Purpose buckets use what is called as Flat Storage Structure, where it organize all files at the same level, without directories or subdirectories, akin to placing all documents in a single folder. Relies on metadata tags and unique identifiers to categorize and retrieve files, compensating for the lack of nested directories.
Directory Buckets
Directory buckets support bucket creation in the following bucket location types: Availability Zone or Local Zone.
For low latency use cases, you can create a directory bucket in a single Availability Zone to store data. Directory buckets in Availability Zones support the S3 Express One Zone storage class. S3 Express One Zone storage class is recommended if your application is performance-sensitive and benefits from single-digit millisecond PUT and GET latencies.
Directory buckets organize data hierarchically into directories as opposed to the flat storage structure of general-purpose buckets. There aren’t prefix limits for directory buckets, and individual directories can scale horizontally.
You can create up to 100 directory buckets in each of your AWS accounts, with no limit on the number of objects that you can store in a bucket. Your bucket quota is applied to each Region in your AWS account. If your application requires increasing this limit, contact AWS Support.

Directories
Directories
Directory buckets organize data hierarchically into directories instead of using the flat structure of general-purpose buckets.
Hierarchical Namespace
With a hierarchical namespace, the delimiter in the object key plays an important role. The only supported delimiter is a forward slash (/). Directories form at delimiter boundaries.
For example, the object key dir1/dir2/file1.txt creates the directories dir1/ and dir2/ automatically. The object file1.txt is then added inside the /dir2 directory at the path dir1/dir2/file1.txt.
Indexing Model
The directory bucket indexing model returns unsorted results when you run the ListObjectsV2 API operation. To limit your results to a subsection of the bucket, you can specify a subdirectory path in the prefix parameter. For example:
prefix=dir1/Key Names
For directory buckets, the system creates subdirectories that are common to multiple object keys when the first object key is added. Later object keys that share the same subdirectory use the already created subdirectory.
This model gives you flexibility to choose object keys that best match your application. It works equally well for both sparse and dense directories.
Use cases for directory buckets
For low latency use cases, you can create a directory bucket in a single Availability Zone to store data. Directory buckets in Availability Zones support the S3 Express One Zone storage class. S3 Express One Zone storage class is recommended if your application is performance sensitive and benefits from single-digit millisecond PUT and GET latencies.
High-performance workloads
Amazon S3 Express One Zone is a high-performance, single-zone storage class designed for latency-sensitive applications. It offers the highest possible access speed by co-locating object storage with compute resources in a single Availability Zone.
Key benefits include:
- Low Latency: Provides single-digit millisecond data access, up to 10x faster than S3 Standard.
- Cost Efficiency: Request costs are 50% lower than S3 Standard.
- Performance Elasticity: Similar to other S3 storage classes.
- Redundancy: Handles concurrent device failures by shifting requests to new devices within the same Availability Zone.
Ideal for applications requiring minimal latency, such as:
- Human-Interactive Workflows: Video editing and other creative tasks.
- Analytics and Machine Learning: Workloads with frequent or random data accesses.
S3 Express One Zone can be integrated with AWS services like Amazon EMR, Amazon SageMaker, and Amazon Athena to support analytics and AI/ML workloads.
For optimal performance, specify an AWS Region and Availability Zone local to your compute instances (e.g., Amazon EC2, Amazon EKS, or Amazon ECS). You can access S3 Express One Zone directory buckets from a VPC using a gateway VPC endpoint, avoiding the need for an internet gateway or NAT device.
Appending data to objects in directory buckets
You can append data to existing objects in S3 Express One Zone directory buckets. This is useful for continuously written data or when you need to read while writing, such as adding log entries or video segments.
Key points:
- No Minimum Size: Append any size data, up to 5GB per request.
- Maximum Parts: Each object can have up to 10,000 parts.
- Multipart Upload: Parts from multipart uploads count towards the 10,000 parts limit.
If you reach the limit, you’ll get a TooManyParts error. Use the CopyObject API to reset the count.
For parallel uploads without reading parts during upload, use Amazon S3 multipart upload.
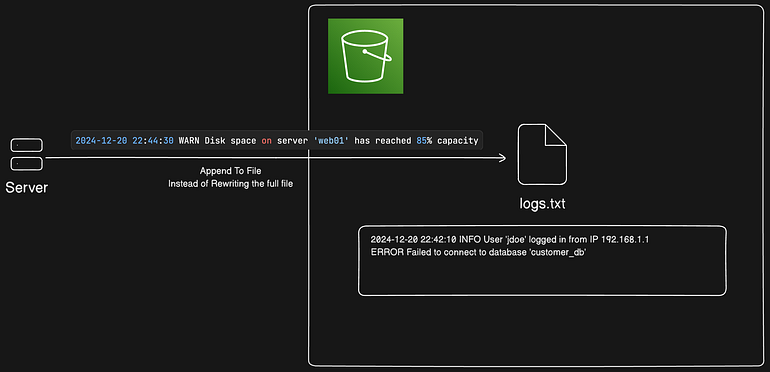
Appending is supported only for objects in S3 Express One Zone directory buckets
S3 Table Buckets
Amazon S3 Tables provide S3 storage that’s optimized for analytics workloads, with features designed to continuously improve query performance and reduce storage costs for tables. S3 Tables are purpose-built for storing tabular data, such as daily purchase transactions, streaming sensor data, or ad impressions. Tabular data represents data in columns and rows, like in a database table.
The data in S3 Tables is stored in a new bucket type: a table bucket, which stores tables as subresources. Table buckets support storing tables in the Apache Iceberg format. Using standard SQL statements, you can query your tables with query engines that support Iceberg, such as Amazon Athena, Amazon Redshift, and Apache Spark.
Table buckets are used to store tabular data and metadata as objects for use in analytics workloads. Table buckets are comparable to data warehouses in analytics
Features of S3 Tables
S3 Tables comes with a pre-built features:
- Purpose-built storage for tables
- Built-in support for Apache Iceberg
- Automated table optimization
- Access management and security
- Integration with AWS analytics services
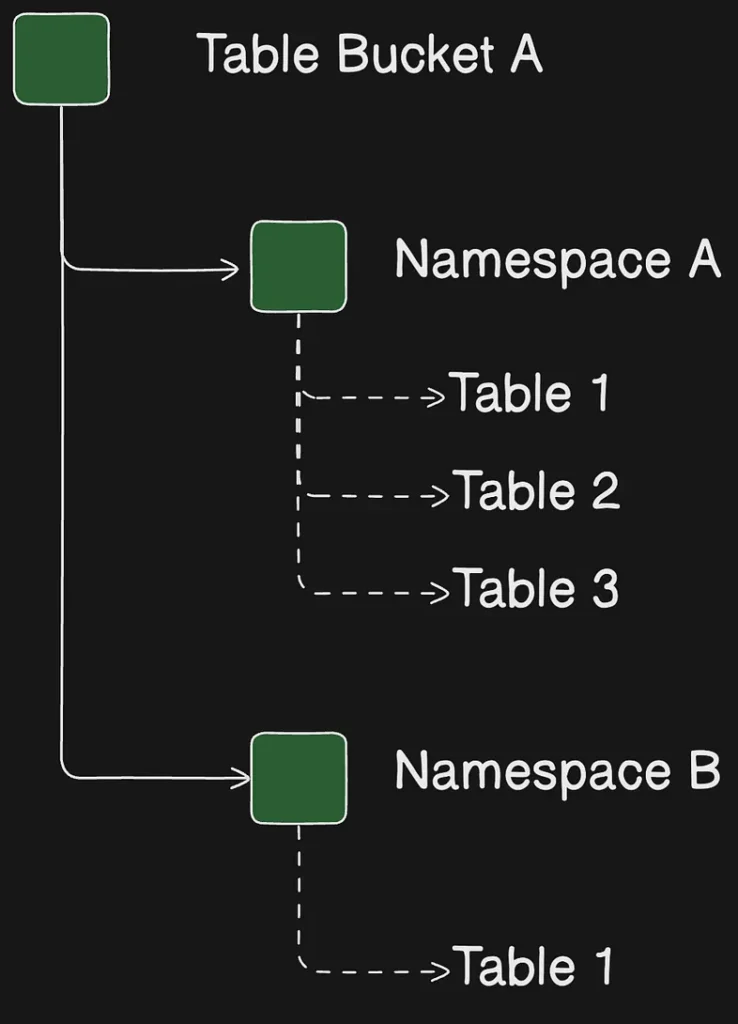
S3 Tables Namespaces
When you create tables within your table bucket, you organize them into logical groupings called namespaces. Unlike S3 tables and Table buckets, namespaces are not resources, they are constructs that help you organize and manage your tables in a scalable manner. For example, all the tables belonging to the HR department in a company could be grouped under a common namespace value of hr.
You can use table bucket resource policies to limit access to specific namespaces.
Comprehensive S3 Buckets Comparison
Given the complexity and variety of S3 buckets, it is essential to have a thorough comparison to understand their specific use cases and optimal usage scenarios. This summary provides an in-depth analysis of the key differences between the various S3 bucket types offered by AWS, enabling you to make informed decisions on when and how to utilize each bucket effectively.
| Feature | General Purpose Buckets | Directory Buckets | Table Buckets |
|---|---|---|---|
| Description | The original S3 bucket type, suitable for a wide range of applications and access patterns. | Optimized for low-latency applications, storing data within a single Availability Zone. | Purpose-built for storing tabular data, optimized for analytics and machine learning workloads. |
| Storage Classes | Supports all storage classes except S3 Express One Zone. | Supports the S3 Express One Zone storage class. | Specific to table storage needs, often utilizing formats like Apache Iceberg. |
| Data Organization | Employs a flat storage structure without inherent hierarchical organization. | Utilizes a hierarchical namespace, organizing data into directories. | Stores data in a structured, tabular format, facilitating efficient querying. |
| Performance | Designed for general workloads with standard performance needs. | Offers single-digit millisecond latencies for PUT and GET operations, supporting high request rates. | Provides higher transactions per second (TPS) and improved query throughput compared to self-managed tables in S3 buckets. |
| Use Cases | Ideal for most applications, including backups, content storage, and data archiving. | Suitable for performance-sensitive applications requiring rapid access, such as real-time analytics and ML. | Ideal for data lakes, analytics, and ML applications requiring efficient table storage and querying capabilities. |
| Availability Zone | Data is stored across multiple Availability Zones, providing high durability and availability. | Data is stored in a single Availability Zone, which may reduce durability and availability compared to GP buckets. | Data is stored across multiple Availability Zones, ensuring high durability and availability. |
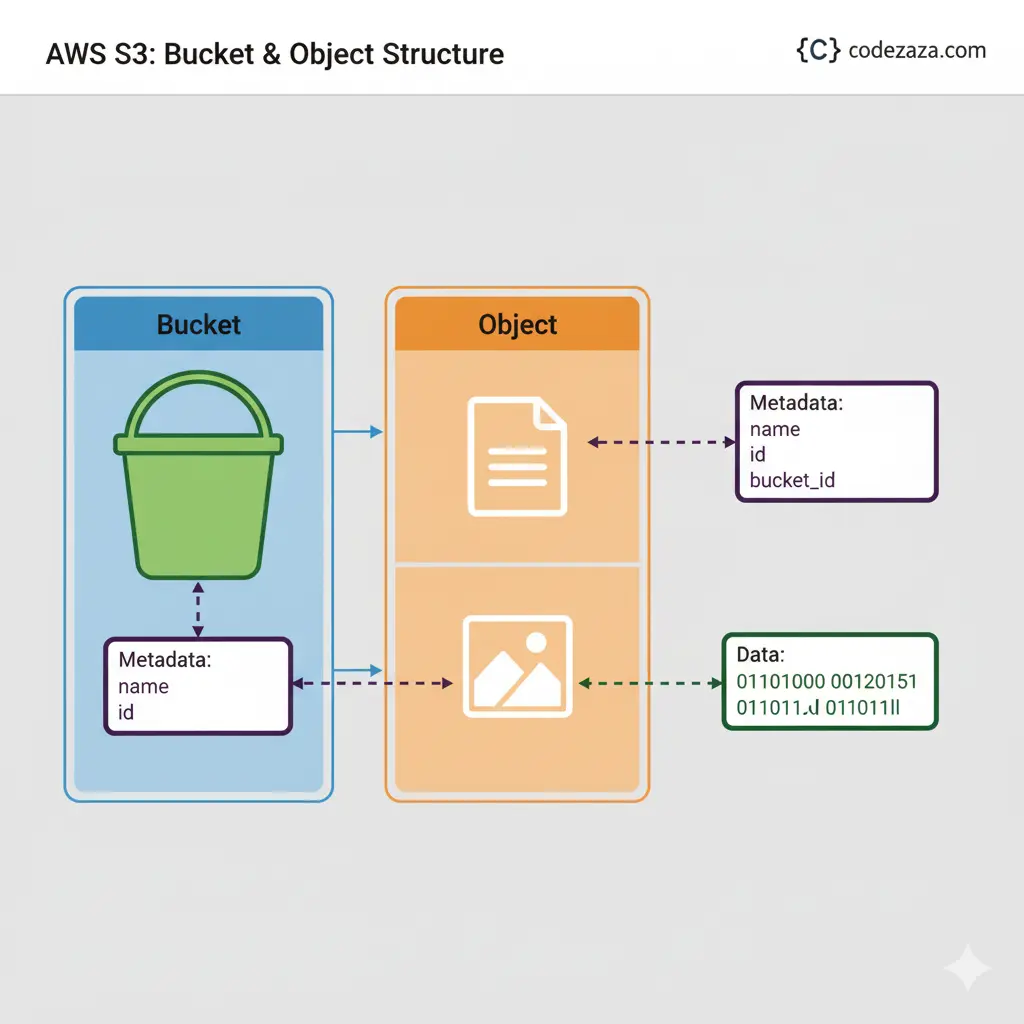
Objects in S3
To store your data in Amazon S3, you work with resources known as buckets and objects. A bucket is a container for objects. An object is a file and any metadata that describes that file.
To store an object in Amazon S3, you create a bucket and then upload the object to a bucket. When the object is in the bucket, you can open it, download it, and copy it. When you no longer need an object or a bucket, you can clean up these resources.
Amazon S3 objects overview
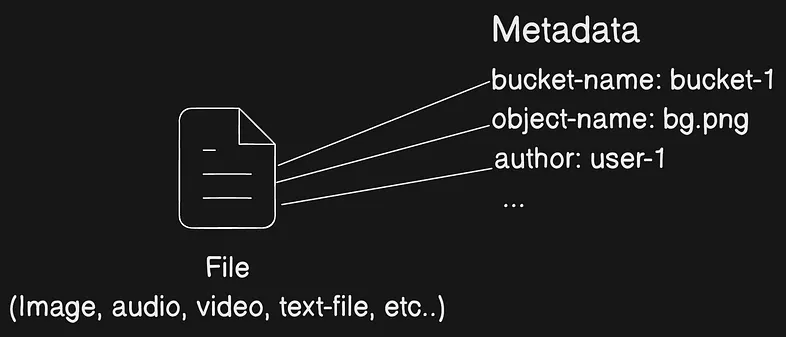
Amazon S3 is an object store that uses unique key-values to store as many objects as you want. You store these objects in one or more buckets, and each object can be up to 5 TB in size. An object consists of the following:
Key
The name that you assign to an object. You use the object key to retrieve the object.
Version ID
Within a bucket, a key and version ID uniquely identify an object. The version ID is a string that Amazon S3 generates when you add an object to a bucket.
Value
The content that you are storing.
An object value can be any sequence of bytes. Objects can range in size from zero to 5 TB.
Metadata
A set of name-value pairs with which you can store information regarding the object. You can assign metadata, referred to as user-defined metadata, to your objects in Amazon S3. Amazon S3 also assigns system-metadata to these objects, which it uses for managing objects.
Subresources
Amazon S3 uses the subresource mechanism to store object-specific additional information. Because subresources are subordinates to objects, they are always associated with some other entity such as an object or a bucket.
Access control information
You can control access to the objects you store in Amazon S3. Amazon S3 supports both the resource-based access control, such as an access control list (ACL) and bucket policies, and user-based access control.
Your Amazon S3 resources (for example, buckets and objects) are private by default. You must explicitly grant permission for others to access these resources.
Tags
You can use tags to categorize your stored objects, for access control, or cost allocation.
let us explore each of these properties in detail and then talk about specific actions related to objects in S3
Object metadata
There are two kinds of object metadata in Amazon S3: system-defined metadata and user-defined metadata.
System-defined metadata includes metadata such as the object’s creation date, size, and storage class.
User-defined metadata is metadata that you can choose to set at the time that you upload an object. This user-defined metadata is a set of name-value pairs.
When you create an object, you specify the object key (or key name), which uniquely identifies the object in an Amazon S3 bucket.
After you upload the object, you can’t modify this user-defined metadata. The only way to modify this metadata is to make a copy of the object and set the metadata.
By default, S3 Metadata provides system-defined object metadata, such as an object’s creation time and storage class, and custom metadata, such as tags and user-defined metadata that was included during object upload. S3 Metadata also provides event metadata, such as when an object is updated or deleted, and the AWS account that made the request.
How To Use an Amazon S3 Bucket?
You can use the Amazon S3 buckets by following the simple steps which are mentioned below. To know more how to configure about Amazon S3 refer to the Amazon S3 – Creating a S3 Bucket.
Step 1: Login into the Amazon account with your credentials and search form S3 and click on the S3. Now click on the option which is “Create bucket” and configure all the options which are shown while configuring.
Step 2: After configuring the AWS bucket now upload the objects into the buckets based upon your requirement. By using the AWS console or by using AWS CLI following is the command to upload the object into the AWS S3 bucket.
aws s3 cp <local-file-path> s3://<bucket-name>/
Step 3: You can control the permissions of the objects which was uploaded into the S3 buckets and also who can access the bucket. You can make the bucket public or private by default the S3 buckets will be in private mode.
Step 4: You can manage the S3 bucket lifecycle management by transitioning. Based upon the rules that you defined S3 bucket will be transitioning into different storage classes based on the age of the object which is uploaded into the S3 bucket.
Step 5: You need to turn to enable the services to monitor and analyze S3. You need to enable the S3 access logging to record who was requesting the objects which are in the S3 buckets.
Advantages of Amazon S3
- Scalability: Amazon S3 can be scalable horizontally which makes it handle a large amount of data. It can be scaled automatically without human intervention.
- High availability: AmazonS3 bucket is famous for its high availability nature you can access the data whenever you required it from any region. It offers a Service Level Agreement (SLA) guaranteeing 99.9% uptime.
- Data Lifecycle Management: You can manage the data which is stored in the S3 bucket by automating the transition and expiration of objects based on predefined rules. You can automatically move the data to the Standard-IA or Glacier, after a specified period.
- Integration with Other AWS Services: You can integrate the S3 bucket service with different services in the AWS like you can integrate with the AWS lambda function where the lambda will be triggered based upon the files or objects added to the S3 bucket.
Conclusion
Amazon S3 provides a flexible and powerful storage solution that meets a wide range of application needs. With General Purpose Buckets, you get reliable, multi-AZ storage for most workloads. Directory Buckets offer low-latency performance ideal for real-time and performance-sensitive applications, while Table Buckets are optimized for analytics and machine learning by efficiently managing structured, tabular data.
By choosing the right bucket type based on your workload—whether it’s backups, content storage, analytics, or machine learning—you can balance performance, durability, and cost. Combined with S3’s global availability and seamless integration with other AWS services, it remains one of the most versatile and essential services in the AWS ecosystem.
