
In Kubernetes, a Job acts as a controller that supervises and manages tasks. It creates Pods, monitors their progress, and replaces them if any fail. Once the task completes, the Job automatically terminates the Pods. Unlike Deployments or standalone Pods, a Job can be configured as a one-time task, a time-based task, or a specific task-based job. This setup helps ensure reliability and fault tolerance against unexpected pod failures.
When you submit a Job, it launches one or more Pods based on the configuration. These Pods run until they complete the defined task. The Job tracks each successful completion and records it. If the Job is suspended, Kubernetes deletes all active Pods and recreates them when the Job restarts.
Job Types
1. Non-Parallel Job:
This is a simple job that defines a single task. It creates one Pod that runs the task and terminates automatically once the job completes successfully.
2. Parallel Job with Fixed Completion Count:
This job type handles complex tasks that require multiple Pods to run in parallel. Each Pod gets a unique index ranging from 0 to .spec.completions - 1, as defined in the .spec.completions field. The job completes successfully when the required number of Pods finish their tasks.
3. Parallel Job with a Work Queue:
In this type, multiple Pods work together in parallel to process a set of dependent or complex data. Each Pod coordinates with other Pods or an external service to determine its workload. For example, a Pod may pull a batch of N items from a shared work queue. Each Pod can also check whether all others have finished, helping determine when the entire Job is complete
Core Concepts Of Kubernetes Jobs
Completion: To be considered the task completed, Pods are required to for confirming the Specifies the desired number of completed.
Pod Templates: To create the Pods that will perform the actual tasks, it is required to Tasks use a pod template.
Parallelism: This handles the maximum number of pods that can run to execute tasks.
Restart Policy: This is very useful, for the behavior of Pods, when the task fails, it can restart the task.
Key Terminologies:
There are a few key terminologies we are using throughout the article.
- Kubernetes: Kubernetes is an open-source system, from Google for orchestrating containers. Allow automation of most of the operational tasks around containerized applications.
- Pods: The smallest deployable compute units that Kubernetes allows you to construct and control are called pods. It can be a single container or a combination of containers.
- Minikube: A local version of Kubernetes to get you started and testing your work locally.
Steps To Setup Job:
Today, we will consider an example of setting up a job that will use Docker Busybox image and ping geeksforgeeks.org.
Step1. Create Kind Cluster
$ kind create cluster cluster_name
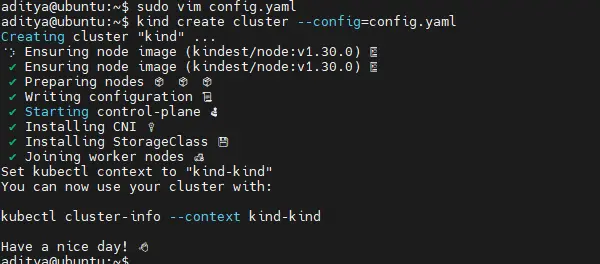
Step2. Create the job definition file in YAML format.
$ cat ping-job.yaml
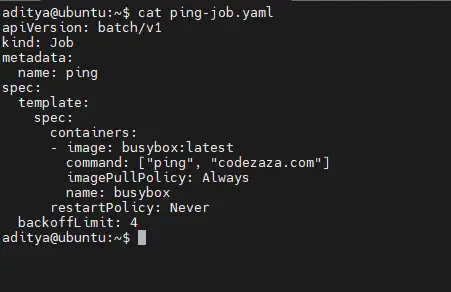
Step4. List the job using get jobs, we can see the no of completion of our job as well as the duration and age.
$ kubectl get jobs
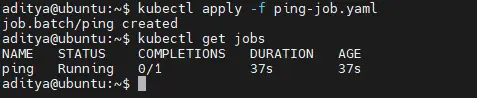
Step5. Get the job details.
$ kubectl describe job ping
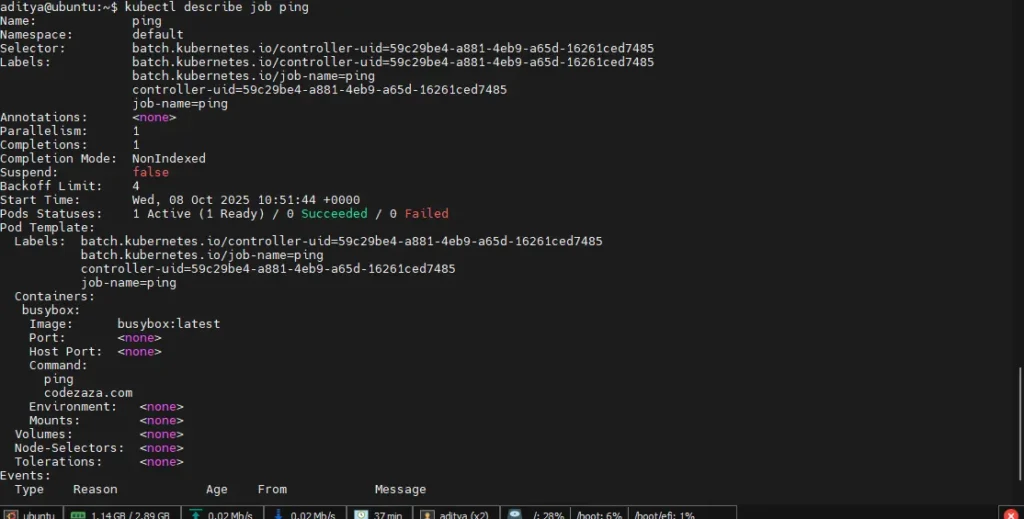
Step6. Get the pods running for our jobs, here you can see the pod name, how many containers, its status, whether its restarted or not, and the age of the pod.
$ kubectl get pods
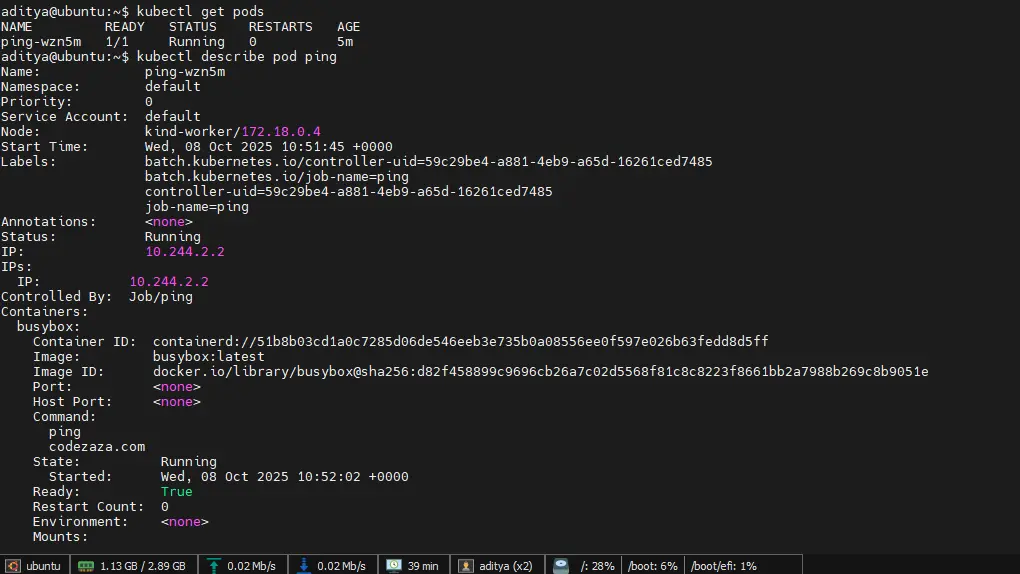
You can check the logs of the container.
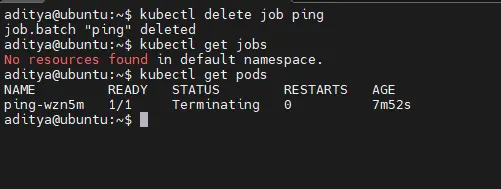
To delete the job use kubectl delete command, If you delete the job, the pods associated with it will be deleted as well.
$ kubectl delete job ping $kubectl get job
Use Cases For Kubernetes Jobs
- Kubernetes jobs are used to periodically back up and restore data.
- Performing data processing or data analysis tasks in a distributed manner.
- It runs batch jobs such as report generation or image processing.
- Performing complex or resource-intensive tasks that require parallelism.
Here is an example of what the YAML file of Kubernetes Jobs looks like;
apiVersion: batch/v1 ## Version of Kubernetes API
kind: Job ## The type of object for jobs
metadata:
name: job-test
spec:
template:
metadata:
name: job-test
spec:
containers:
- name: job
image: busybox
command: ["echo", "job-test"]
restartPolicy: OnFailure ## Restart Policy in case container failed
What Is Cronjobs In Kubernetes?
CronJobs in Kubernetes is used for the scheduling and automation of recurring jobs. CronJobs is especially used for periodic maintenance automatically, data synchronization, or any task that needs to run in any specific time interval.
Core Concepts of Kubernetes CronJobs
1. Job Templates:
A CronJob in Kubernetes relies on a job template that defines how each job should be executed. This template includes specifications such as the container image, commands, restart policy, and environment variables. Each scheduled run of the CronJob creates a new Job object, which in turn creates one or more Pods to perform the defined task.
2. Schedule:
The schedule determines when and how often the CronJob should run. It uses the standard cron time format (minute hour day month day-of-week), allowing you to define intervals ranging from every minute to specific dates or times. For example, "*/5 * * * *" runs every five minutes, while "0 0 * * *" runs once daily at midnight.
3. Start Timeout Seconds:
This parameter defines the maximum time Kubernetes will wait for a job to start after its scheduled time. If the job fails to begin within the specified timeout, Kubernetes considers it missed or failed. This prevents overlapping or delayed job executions in environments with high load or scheduling delays.
4. Concurrency Policy (Additional Concept):
CronJobs can control how concurrent executions are handled using the concurrencyPolicy field.
Allow– permits multiple runs to overlap.Forbid– skips new runs if the previous one is still active.Replace– cancels the currently running job and starts a new one.
This helps ensure that tasks such as data synchronization or backups don’t run simultaneously and cause conflicts.
5. Successful and Failed Job History:
You can manage how many successful and failed job runs are retained in the system using successfulJobsHistoryLimit and failedJobsHistoryLimit. Keeping these limits low ensures the cluster doesn’t accumulate unnecessary job records over time.
Use Cases for Kubernetes CronJobs
1. Automated Backups and Data Synchronization:
CronJobs are widely used to perform scheduled database backups, file system snapshots, or synchronization between systems. For instance, a CronJob might run nightly to back up data from a production database to a remote storage bucket.
2. Routine System Maintenance:
Tasks such as log rotation, temporary file cleanup, or pruning unused Docker images can be automated through CronJobs. This helps maintain system performance and prevent resource exhaustion.
3. Periodic Data Aggregation and Reporting:
Many organizations use CronJobs to collect metrics, aggregate analytical data, or generate scheduled reports. These jobs may fetch data from multiple services, process it, and store the results for dashboards or auditing purposes.
4. Automated Alerts and Notifications:
CronJobs can trigger periodic health checks and send alerts via email or messaging platforms if specific thresholds are breached. This adds an extra layer of monitoring beyond real-time observability tools.
5. Resource Optimization Tasks:
They can run scheduled scripts to scale down non-critical environments (like staging) during off-hours to save cloud costs, then scale them back up automatically during business hours.
Setting Up and Configuring Kubernetes Jobs and CronJobs: Step-by-Step Guide
Step-by-Step Guide for Kubernetes Jobs
1. Create a YAML file for the Job:
nano job-test.yaml
2. Add Job configuration: Add the following content to your job-test.yaml file:
apiVersion: batch/v1 ## Version of Kubernetes API
kind: Job ## The type of object for jobs
metadata:
name: job-test
spec:
template:
metadata:
name: job-test
spec:
containers:
- name: job
image: busybox
command: ["echo", "job-test"]
restartPolicy: OnFailure ## Restart Policy in case container failed
3. Apply the Job
kubectl apply -f job-test.yaml
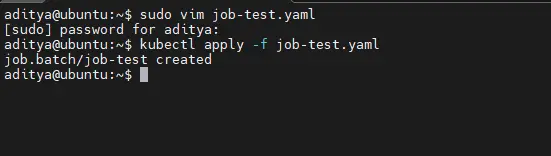
4. Verify the Job
kubectl get jobs
kubectl describe job job-test
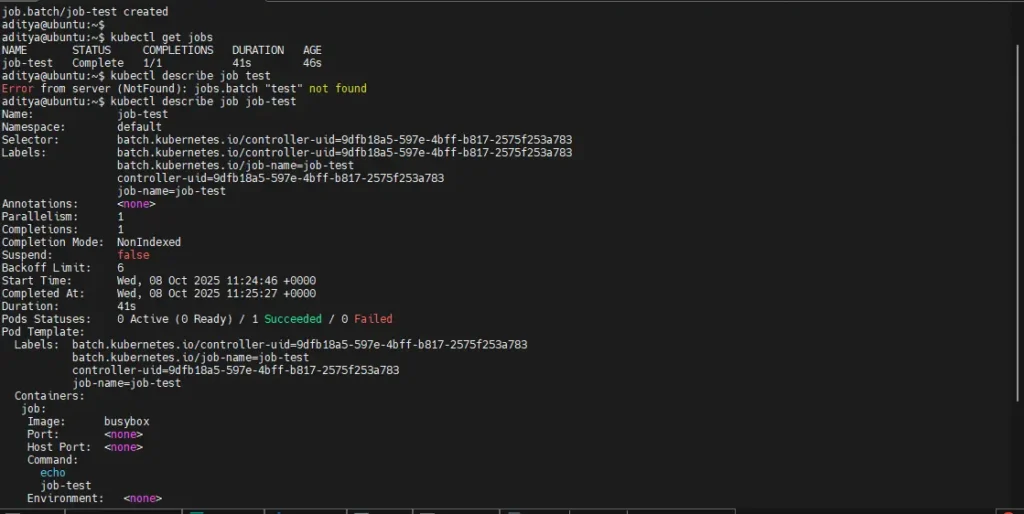
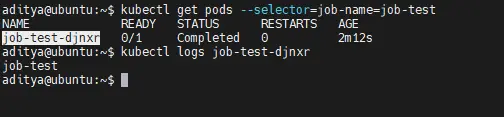
5. Check Logs of the Job Pod
kubectl get pods --selector=job-name=job-test
kubectl logs <pod-name>
Step-by-Step Guide for Kubernetes CronJobs
1. Create a YAML file for the CronJob
vim cronjob.yaml
2. Add CronJob configuration: Add the following configuration to the cron-test.yaml file.
apiVersion: batch/v1
kind: CronJob
metadata:
name: cron-test
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
ttlSecondsAfterFinished: 300
template:
spec:
containers:
- name: cron-test
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello this is Cron test
restartPolicy: OnFailure ## Restart Policy
3. Apply the CronJob
kubectl apply -f cronjob.yaml
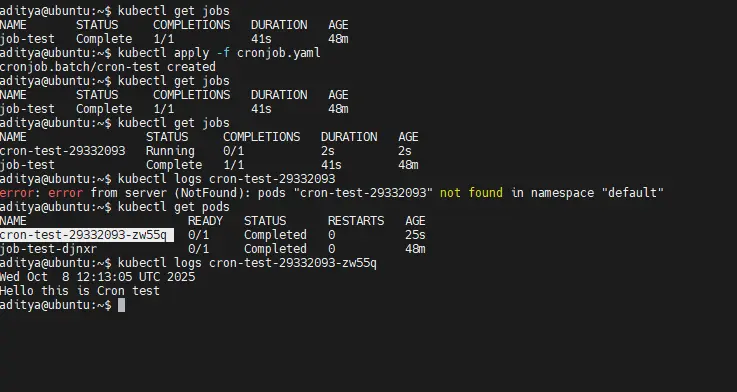
4. Get list of jobs
kubectl get jobs
5. Check Logs for the Pod
kubectl logs cron-test-29332093-zw55q
Conclusion
In Kubernetes, Jobs and CronJobs provide robust mechanisms for executing tasks reliably and automatically.
A Job acts as a controller that supervises Pods, ensures tasks complete successfully, and replaces Pods if they fail. Jobs can be configured as single-run tasks, parallel tasks, or tasks that coordinate via work queues. This design ensures fault tolerance and task completion tracking. Key concepts include Pod templates, completion counts, parallelism, and restart policies. Jobs are ideal for batch processing, data analysis, report generation, and other time-bound tasks.
CronJobs extend Jobs by adding scheduling capabilities, allowing tasks to run periodically at specified intervals using standard cron syntax. CronJobs include additional features such as concurrency policies, start timeouts, and job history management. They are commonly used for automated backups, routine maintenance, periodic reporting, and resource optimization.
