
In Kubernetes, etcd acts as the single source of truth. It forms the backbone of the cluster’s control plane. Every decision Kubernetes makes — from scheduling pods to updating deployments — relies on the data stored in etcd. It is a highly available, distributed key-value store that keeps track of the cluster’s state. This includes nodes, pods, services, secrets, ConfigMaps, and other resources. Think of etcd as the brain of Kubernetes. It remembers the cluster’s desired state and ensures all components operate in harmony.
Unlike traditional databases, etcd is built for high consistency and fault tolerance. It uses consensus algorithms to replicate data across multiple nodes. This means that even if some nodes fail, the cluster can continue running without losing data. These features make etcd critical for reliability, consistency, and smooth orchestration of workloads.
In this blog, we will explore how etcd works under the hood. We’ll cover how it stores cluster state, performs leader election, maintains data consistency, and how administrators can implement backup and recovery strategies. Understanding etcd’s role provides deeper insight into the foundation of Kubernetes.
What is Etcd
Implementing it as a fact-based version that could perform distributed tasks isn’t a small mission. But etcd is constructed for overall performance and has been engineered from the ground up to have the following functions: Fully replicated: Each node in the etcd cluster has access to the full statistics garage. Basically, select etcd to store metadata or hook up with a particular utility. Choose the NewSQL database if you keep more than a few GB of records or need complete SQL queries. Zookeeper offers robust consistency, a easy API, and a mature ecosystem, even as etcd gives a linear, rich API and easy integration with Kubernetes. Both are dependable systems appropriate for connecting and invoking offerings in disbursed applications.
Kubernetes improves on the most common way of dealing with these responsibilities by planning errands, for example, design, sending, administration revelation, load adjusting, position booking, and wellbeing observation across all groups, which can run on numerous machines in various areas. However, to accomplish this coordination, Kubernetes needs an information store that gives a solitary, reliable wellspring of reality with regards to the situation with the framework—every one of its bunches and units and the application cases inside them—at some random moment. etcd is the information store used to make and keep up with this variant of reality.
etcd serves a comparative job for Cloud Foundry (interface lives outside ibm.com)—the open source, multi-cloud Stage as an Administration (PaaS)—and is a feasible choice for planning basic framework and metadata across bunches of any dispersed application. The name “etcd” comes from a naming convention inside the Linux registry structure: In UNIX, all framework setup documents for a solitary framework are contained in an envelope called “/and so on;” “d” means “circulated.”
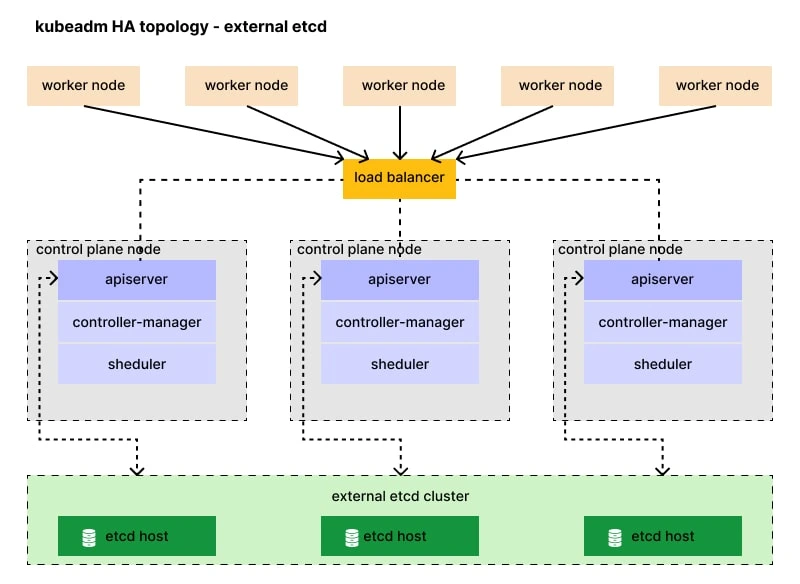
Role of etcd in Kubernetes
In Kubernetes, etcd acts as the primary data store for the entire cluster. It stores all critical information, including cluster state, configuration, metadata, and performance metrics. Kubernetes components rely on etcd to read and update this data consistently, ensuring that the cluster operates reliably.
etcd enables Kubernetes to maintain a single source of truth. It tracks the current and desired state of nodes, pods, services, and other resources. This allows Kubernetes to make accurate scheduling decisions, handle scaling, perform self-healing, and maintain high availability across the cluster.
Because etcd is distributed and highly available, it replicates data across multiple nodes, providing fault tolerance. Even if some nodes fail, Kubernetes can recover the cluster state from the remaining etcd nodes, ensuring uninterrupted operations.
Understanding etcd in Kubernetes
At its core, etcd is a distributed key-value store designed for high availability, consistency, and fault tolerance. Unlike a traditional database that is primarily used for general-purpose storage, etcd is optimized for storing small amounts of critical configuration and state data that must be highly reliable and consistent across a distributed system.
Kubernetes depends on etcd as its primary data store. It holds the cluster’s state and configuration, essentially acting as the cluster’s memory. Without etcd, the control plane cannot make informed decisions about the cluster’s resources or workloads.
Here are the main types of data etcd manages:
1. Cluster State
Etcd tracks the current state of all Kubernetes resources. This includes:
Nodes: Details about each node in the cluster, such as labels, capacity, and status.
Pods: Metadata and status of each pod, including which nodes they are scheduled on and their current lifecycle phase.
Deployments and ReplicaSets: Desired and actual replica counts, update strategies, and rollout status.
Services and Endpoints: IP mappings, service selectors, and cluster networking information.
Persistent Volume Claims (PVCs): Data about storage requests and bindings.
In essence, etcd acts like a map of the entire cluster, storing the “desired state” and “current state” of every resource. Kubernetes controllers continuously query etcd to ensure the actual state matches the desired state.
2. Configuration Data
Etcd also stores Kubernetes’ declarative configuration data, which includes:
ConfigMaps: Arbitrary configuration key-value pairs that applications can read.
Secrets: Sensitive data such as passwords, tokens, and certificates.
Resource definitions: YAML or JSON manifests for deployments, services, and other objects.
By keeping this data in etcd, Kubernetes ensures that configuration is centrally managed, versioned, and consistently available across all control plane nodes.
3. Leader Election Metadata
etcd itself can run in a cluster of nodes for high availability. It uses the Raft consensus algorithm to elect a leader among its nodes.
The leader handles all write operations.
Followers replicate data from the leader and respond to read requests.
Kubernetes control plane components, such as the scheduler and controller manager, rely on etcd’s leader election metadata to avoid conflicts. For example, only one scheduler can assign pods at a time, and etcd ensures this by maintaining leader election records.
Why etcd is the “Brain” of Kubernetes
In a Kubernetes cluster, etcd works as the central nervous system that keeps every component connected and aware of what’s happening. It constantly shares information between the API server, the scheduler, and the controller manager, ensuring they operate in harmony.
First of all, etcd remembers the state of every node and resource. It stores detailed information about pods, services, configurations, and secrets. This data forms the foundation of how Kubernetes understands and manages workloads across the cluster.
Moreover, etcd keeps all components in sync. By acting as a single, consistent source of truth, it allows the control plane to communicate efficiently and avoid conflicts. As a result, the entire cluster behaves predictably, even during rapid changes or scaling events.
etcd provides reliable data for decision-making. It uses the Raft consensus algorithm to confirm that every update is replicated and approved by a majority of nodes. Therefore, each component always reads the most recent and accurate state of the cluster.
Without etcd, Kubernetes quickly loses its ability to coordinate or recover from failures. The cluster would not know which workloads exist, where they run, or what configuration they require. In simple terms, losing etcd is like wiping the cluster’s memory clean — no deployments, services, or configurations could be recovered without a backup.
How etcd Stores Cluster State
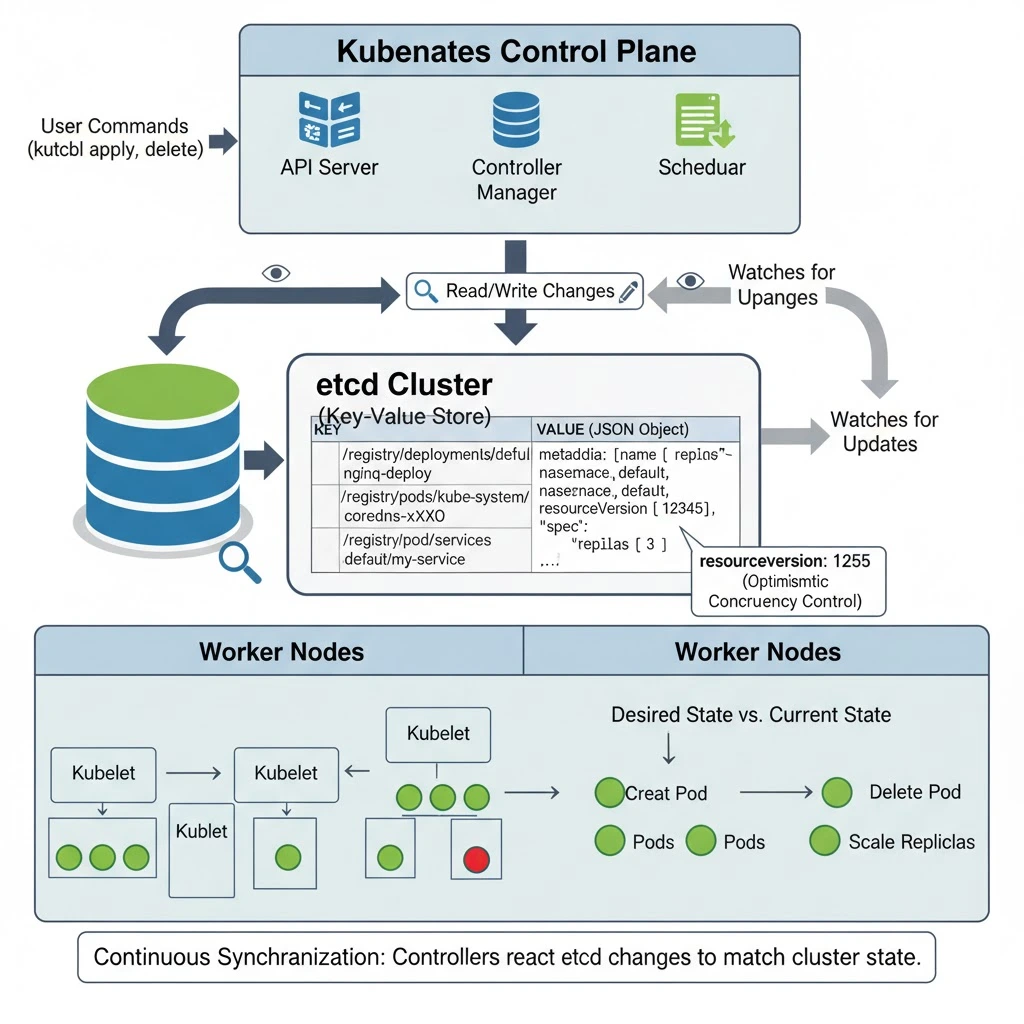
etcd organizes all Kubernetes data using a key-value structure, similar to how a dictionary works. Every piece of cluster information — whether it’s a Pod, Deployment, Service, or ConfigMap — is stored as a unique key in etcd. This structure allows Kubernetes to quickly retrieve and update data whenever a change happens.
Key-Value Format
Each Kubernetes resource is stored using a specific key naming pattern:
/registry/<resource_type>/<namespace>/<resource_name>This naming convention keeps the data well-organized and easy to locate.
For example, if you create a Deployment called nginx-deploy in the default namespace, the corresponding etcd key will look like this:
/registry/deployments/default/nginx-deployThis key points to the resource’s full serialized JSON object, which represents the desired state of that Deployment.
Example of Stored Data
Here’s what a sample record for the nginx-deploy Deployment looks like inside etcd:
{
"metadata": {
"name": "nginx-deploy",
"namespace": "default",
"resourceVersion": "12345"
},
"spec": {
"replicas": 3,
"template": {
"spec": {
"containers": [
{
"name": "nginx",
"image": "nginx:1.21"
}
]
}
}
}
}This JSON object contains all the information the Kubernetes control plane needs to manage the resource.
For instance, it defines how many replicas should run, which image to use, and what namespace the resource belongs to.
Data Integrity and Versioning
etcd doesn’t just store raw data; it also attaches metadata like the resourceVersion.
This version number helps Kubernetes maintain optimistic concurrency control.
In simpler terms, it prevents race conditions — if two components try to update the same resource simultaneously, Kubernetes compares the version numbers to ensure that only the latest, valid update is applied.
Continuous Synchronization
Whenever a user creates, modifies, or deletes a Kubernetes object, the API Server writes those changes directly to etcd.
At the same time, Kubernetes controllers continuously watch etcd for updates.
As soon as etcd records a new desired state (for example, a new Pod or Deployment), controllers and schedulers react to make the cluster match that state.
For example:
- If a Deployment in etcd specifies three replicas but only two Pods are running, the controller detects the difference and schedules another Pod.
- If a user deletes a resource, the API Server removes its key from etcd, and the corresponding workload is terminated automatically
Leader Election in etcd
To achieve high availability and fault tolerance, etcd runs as a distributed cluster of nodes. Instead of relying on a single server, it operates using multiple nodes that work together to maintain the same dataset. However, not all nodes perform the same role at the same time — and that’s where leader election comes in.
How Leader Election Works
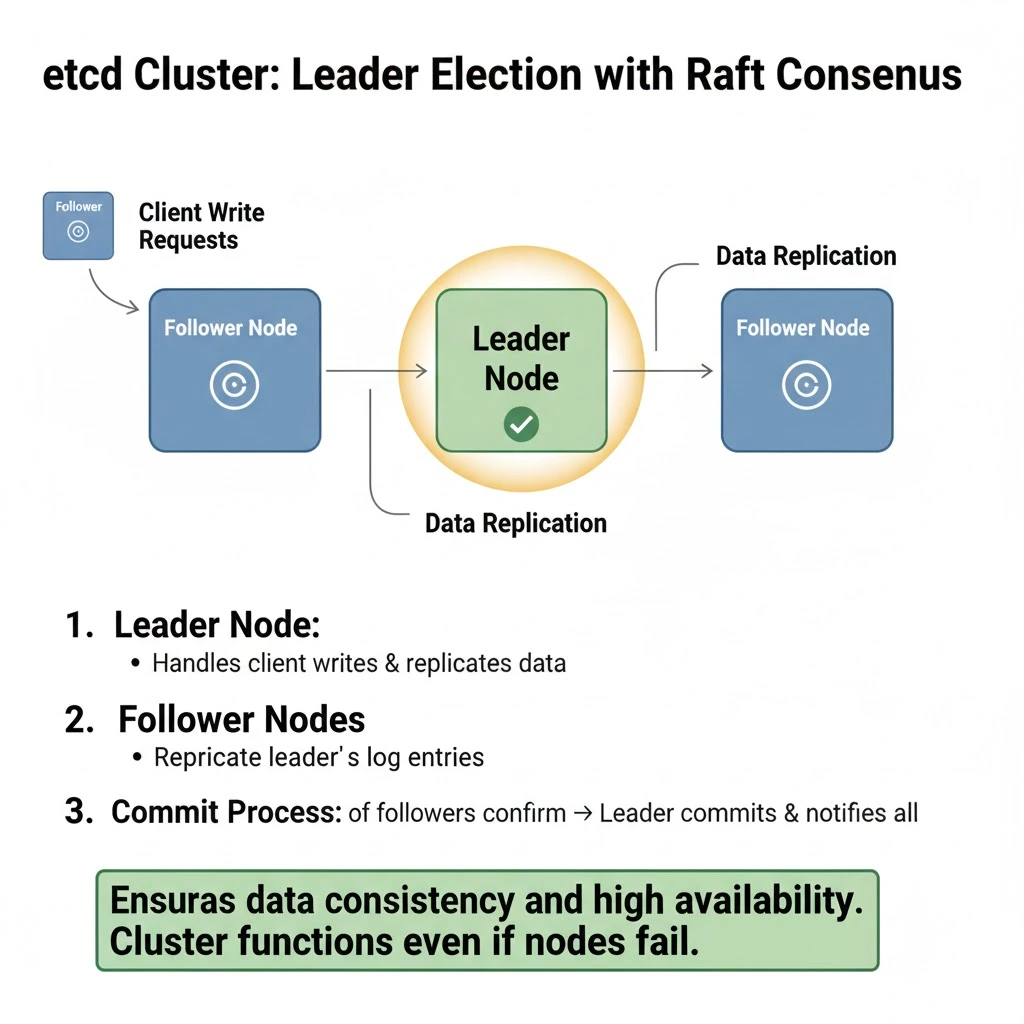
etcd uses the Raft consensus algorithm to manage coordination among its nodes. Raft is designed to ensure that all nodes in a distributed system agree on a single, consistent state, even if some nodes fail or become unreachable.
Here’s how it works step by step:
- Leader Node – One node in the etcd cluster acts as the leader. It handles all client write requests and manages data replication to other nodes. Every time a change is made, such as creating or updating a resource, the leader first writes the change to its own log.
- Follower Nodes – The remaining nodes are followers. They do not process client writes directly. Instead, they replicate the leader’s log entries to maintain a synchronized copy of the data.
- Commit Process – Once the majority of followers (a quorum) confirm that they’ve received the update, the leader commits the change and notifies all nodes. This guarantees that the data is consistent across the cluster.
As a result, even if one or more nodes go offline, etcd continues to function as long as a quorum of nodes is available.
Why Leader Election Matters
The leader election process is essential for maintaining strong consistency. Only one node can be the leader at any given time, which prevents two nodes from making conflicting decisions — a situation known as a split-brain scenario.
This ensures that:
- All write operations flow through a single source of truth (the leader).
- The cluster’s data remains consistent and up to date.
- Followers can safely serve read requests without risking stale or conflicting data.
Because of this mechanism, Kubernetes’ control plane can rely on etcd with complete confidence. Whether it’s scheduling pods, scaling deployments, or updating cluster configurations, Kubernetes always interacts with an etcd cluster that provides consistent, accurate data.
Handling Leader Failures
In a production environment, node failures are inevitable. The Raft algorithm automatically detects when a leader becomes unavailable and triggers a new leader election.
Here’s what happens:
- When the followers stop receiving heartbeats from the leader (indicating a failure or network issue), they hold an election.
- The first follower to receive a majority of votes from other nodes becomes the new leader.
- The new leader continues processing client requests, and data replication resumes seamlessly.
This automatic recovery process ensures minimal downtime and uninterrupted Kubernetes operations.
Etcd Backup Strategies in Kubernetes
Because etcd stores the entire Kubernetes cluster state, regular backups are essential for recovery in case of data corruption, accidental deletion, or node failure. Kubernetes administrators typically use two main backup approaches: snapshot backups and automated backup tools.
1. Snapshot Backup
A snapshot backup captures the entire etcd data store at a specific point in time. It’s one of the most reliable ways to preserve the current cluster state.
Administrators use the etcdctl command-line utility to create and restore snapshots.
Example – Taking a Snapshot:
ETCDCTL_API=3 etcdctl snapshot save /var/lib/etcd/snapshot.db \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.keyThis command saves the current etcd database into a file named snapshot.db. It’s best practice to store this file on external storage, such as an S3 bucket or a remote server.
Example – Restoring from a Snapshot:
ETCDCTL_API=3 etcdctl snapshot restore /var/lib/etcd/snapshot.db \
--data-dir=/var/lib/etcd-from-backupAfter restoration, you can reconfigure the etcd service to use the new data directory and restart the control plane. The cluster will then recover its previous state.
2. Automated Backup Tools
Automated tools help schedule and manage regular etcd backups without manual intervention. They integrate directly with Kubernetes and often include features like encryption, retention policies, and cloud storage support.
Example – Velero:
Velero is a popular open-source tool for backing up and restoring Kubernetes clusters. It not only backs up etcd data (via API objects) but also includes persistent volumes.
To back up the entire cluster:
velero backup create cluster-backup --include-namespaces '*' --waitTo restore from a previous backup:
velero restore create --from-backup cluster-backupVelero stores the etcd and Kubernetes object data in your configured cloud storage (e.g., AWS S3, GCP, or Azure Blob).
Example – Kasten K10:
Kasten K10 provides enterprise-grade automated backups for Kubernetes clusters. It supports scheduled backups, disaster recovery policies, and instant restore operations, making it suitable for production environments.
Etcd Corruption Recovery
Even with redundancy and backups, etcd can occasionally become corrupted due to disk issues, abrupt shutdowns, or hardware failures. When this happens, the Kubernetes API server may fail to start or connect properly, resulting in a cluster outage.
To recover from such situations, administrators can restore etcd to a healthy state from a previously saved snapshot.
a) Detecting Corruption
You can check the health of etcd using the following command:
ETCDCTL_API=3 etcdctl endpoint health \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.keyIf the output shows errors such as “unhealthy” or “corrupt”, you must immediately restore the database from a valid snapshot.
b) Restoring from Snapshot
To restore a corrupted etcd instance:
- Stop the etcd service:
systemctl stop etcd - Restore the snapshot to a new data directory:
ETCDCTL_API=3 etcdctl snapshot restore /tmp/snapshot.db \ --data-dir /var/lib/etcd-from-backup - Update your etcd configuration file (usually
/etc/kubernetes/manifests/etcd.yaml) to point to the new data directory:- --data-dir=/var/lib/etcd-from-backup - Restart etcd:
systemctl start etcd
Once the service starts, the Kubernetes control plane components — including the API server, scheduler, and controller manager — reconnect automatically, restoring normal cluster operations.
c) Example: Restoring etcd in a kubeadm Cluster
In a kubeadm-based Kubernetes setup, you can easily manage etcd snapshots with built-in commands.
Backup:
sudo ETCDCTL_API=3 etcdctl snapshot save /root/snapshot-pre-restore.db \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.keyRestore:
sudo ETCDCTL_API=3 etcdctl snapshot restore /root/snapshot-pre-restore.db \
--data-dir /var/lib/etcd-backupThen modify /etc/kubernetes/manifests/etcd.yaml to reference /var/lib/etcd-backup as the new data directory and restart the control plane.
Best Practices for etcd
1. Run etcd as a Cluster
Always deploy etcd as a multi-node cluster with an odd number of nodes. This ensures quorum during leader elections, fault tolerance, and high availability. A 3-node or 5-node cluster can survive node failures while maintaining cluster consistency.
2. Enable TLS Encryption
Encrypt all communication between etcd nodes and clients using TLS. This protects sensitive cluster data, including secrets and API credentials, from interception and unauthorized access.
3. Schedule Regular Snapshots
Automate backups with frequent snapshots and store them securely offsite. Snapshots provide reliable recovery points in case of corruption or accidental data loss.
4. Monitor etcd Health and Performance
Track metrics such as leader changes, proposal commits, and disk I/O latency using monitoring tools like Prometheus and Grafana. Early detection of anomalies helps prevent downtime and ensures consistent cluster performance.
5. Test Backup and Restore Procedures
Regularly validate backups by performing test restores. This ensures snapshots are usable, the recovery process is understood, and the cluster can be restored quickly in emergencies.
Conclusion
etcd is the heart and brain of Kubernetes, providing a reliable, consistent, and highly available store for all cluster state and configuration data. Its role extends far beyond simple storage: it coordinates control plane components, ensures data consistency through the Raft consensus algorithm, and maintains cluster integrity even during node failures.
Proper management of etcd — including multi-node clustering, TLS encryption, regular snapshots, health monitoring, and tested recovery procedures — is critical to keeping Kubernetes clusters resilient and operational. Backups and corruption recovery strategies ensure that, even in the face of hardware failures or data corruption, administrators can restore the cluster quickly and safely.
By understanding how etcd works and implementing these best practices, Kubernetes users can maintain high availability, consistent operations, and disaster preparedness, ensuring that their clusters remain robust and dependable for all workloads.
