
Kubernetes was built around the Kubernetes API. The Kubernetes API is what allows you to interact, explore and manage your Kubernetes cluster. Even if you’re using tools like kubectl or kubeadm, each of these interacts with the Kubernetes API to effect changes. Because the Kubernetes API is such a critical component for cluster management, it’s essential that you become familiar with what it is, and how it works. This article will introduce you to the API and help you understand how it works.
We’ll start by looking at what the Kubernetes API is and what role it plays in your overall Kubernetes strategy. In addition to explaining what the Kubernetes API can do, we’ll get specific about how to use it to deploy and manage your applications. We’ll also discuss different API commands and give examples that you can use with your Kubernetes environment. Let’s get started.
Importance of Kube API Server
The API server’s value lies in its ability to simplify and standardize cluster management. By offering a single, consistent interface for all interactions, it:
Facilitates Automation: Tools like CI/CD pipelines rely on the it to deploy, update, and scale applications automatically.
Centralizes Control: All cluster operations funnel through the API server, eliminating confusion and redundancy.
Ensures State Consistency: It keeps the desired state (defined by users) and actual state (tracked in etcd) in perfect sync.
Enables Extensibility: Developers can extend Kubernetes through custom resource definitions (CRDs), unlocking endless possibilities for customization.
Supports Scalability: As a cluster grows, the API server scales to handle more requests and interactions seamlessly.
Key Features
- RESTful API Interface: Exposes a comprehensive RESTful API, enabling clients like
kubectl, dashboards, and other tools to interact with the cluster. These APIs support a wide range of operations, from deploying workloads to monitoring cluster health. - Authentication and Authorization: Security is a cornerstone of the server. Every request is authenticated (using tokens, certificates, or other methods) and authorized through role-based access control (RBAC) to ensure only permitted actions are executed.
- State Management: Communicates with etcd, Kubernetes’ key-value store, to read and write the cluster’s state. This ensures the desired configurations are reflected accurately in the running environment.
- Extensibility: By supporting CRDs and aggregated APIs, the API server allows you to introduce custom resources and extend Kubernetes’ capabilities without modifying its core.
- Communication Gateway: Facilitates interaction between various control plane components (like the kube-scheduler and kubelet), ensuring the cluster runs smoothly.
- Versioning and Compatibility: As Kubernetes evolves, the API server supports versioning to maintain compatibility with older tools and components while introducing new features.
How It Works
- Receiving Requests: Accepts HTTP requests from clients, such as users executing
kubectlcommands, applications using the Kubernetes API, or cluster components needing updates. - Authentication and Authorization: Each request undergoes rigorous checks to verify the sender’s identity and permission levels. For instance, a developer might only have access to specific namespaces, while an administrator can perform cluster-wide operations.
- Validation and Admission: Before processing, requests are validated against Kubernetes’ schemas. They may also pass through admission controllers, which enforce organizational policies, such as resource quotas or security constraints.
- State Update: If a request is approved, the API server updates etcd to reflect the desired changes. For example, if a user creates a pod, the API server records this in etcd and informs other components to take action.
- Component Communication: The API server notifies relevant components, such as the kube-scheduler, to take the necessary steps. In our pod example, the scheduler would find a suitable node to run the pod.
How Kubernetes API Requests Are Processed: Validated, Authenticated, and Stored in etcd
Every action in a Kubernetes cluster — from creating a Pod to updating a Deployment — starts with an API request. The Kubernetes API Server acts as the gatekeeper, ensuring that every request is secure, valid, and consistent before it changes cluster state.
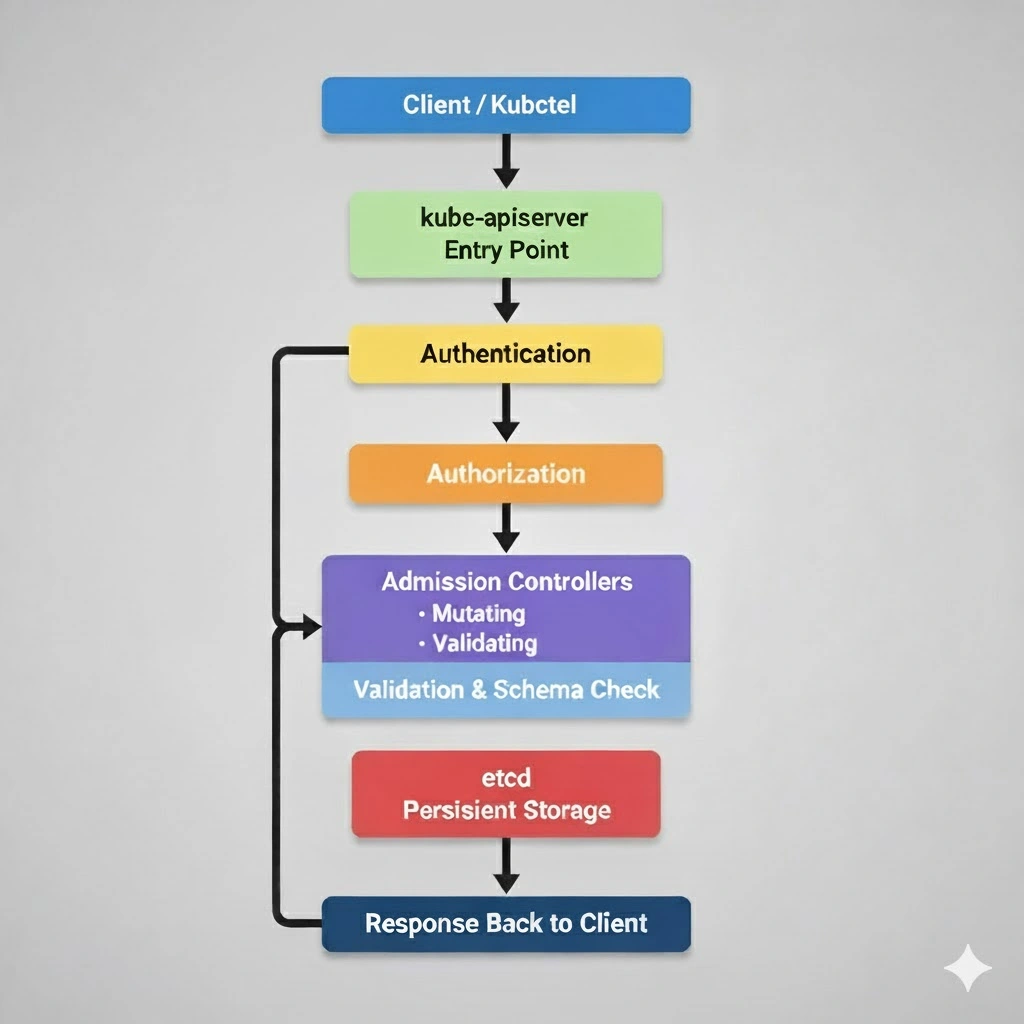
Here’s how it works, step by step:
1. Request Reception: The First Gate
When you run a command like:
kubectl apply -f pod.yamlthe API request is sent to the kube-apiserver over HTTPS. This is the entry point for all cluster operations.
The API server immediately begins processing the request through a well-defined pipeline.
2. Authentication: Verifying Identity
Before doing anything, Kubernetes checks who is making the request.
Supported authentication methods include:
Client certificates for admins and kubelets
Bearer tokens for service accounts
OpenID Connect (OIDC) for enterprise identity providers
Webhook authentication for custom solutions
If the identity cannot be verified, the request is rejected instantly, ensuring that only trusted users or services can interact with the cluster.
3.Authorization: Checking Permissions
After authentication, Kubernetes checks what the user is allowed to do.
Authorization methods include:
RBAC (Role-Based Access Control) — the most common method
ABAC (Attribute-Based Access Control) — legacy, less common
Webhook authorization — delegating decisions to external systems
Example:
kubectl auth can-i create pods --namespace devThis ensures only authorized users can modify cluster resources.
4.Admission Controllers: Enforcing Policies
Once authorized, requests pass through Admission Controllers, the policy enforcers of Kubernetes.
Types:
Mutating Admission Controllers — modify requests, e.g., injecting sidecar containers or default labels
Validating Admission Controllers — validate requests, e.g., ensuring security or namespace quotas
Only after passing admission controllers does the object move closer to persistence.
5.Validation & Schema Enforcement
Before storing the object, the API server validates the request against its schema:
Ensures required fields are present
Checks value types
Converts between API versions if needed
Invalid requests are rejected with clear error messages, protecting cluster integrity.
6.Persistence in etcd: The Source of Truth
After validation, the object is serialized into JSON and stored in etcd, Kubernetes’ distributed key-value store.
Each resource is stored under a specific path, e.g.,
/registry/pods/default/nginxetcd ensures strong consistency, high availability, and watchable state changes for controllers and schedulers.
This is how Kubernetes maintains its desired vs. current state model, enabling automatic reconciliation.
7.Response to Client
Finally, the API server sends a confirmation response to the client, e.g., HTTP 201 Created with metadata and initial status:
{
"kind": "Pod",
"apiVersion": "v1",
"metadata": { "name": "nginx", "namespace": "default" },
"status": { "phase": "Pending" }
}The client now knows the object is safely persisted and ready for the controllers to act.
Admission Controllers
In Kubernetes, Admission Controllers act as vigilant gatekeepers. After the API server authenticates and authorizes a request, admission controllers intercept it before storing the object in etcd. They enforce policies, validate configurations, or modify objects to ensure the cluster remains secure and consistent.
Types of Admission Controllers
Validating Admission Controllers
These controllers check whether a request complies with policies. For example, they can reject pods that request excessive CPU or use forbidden labels. They don’t modify objects—they either approve or deny the request.
Mutating Admission Controllers
These controllers automatically modify objects before storing them. For example, they can inject sidecar containers (like Istio or logging agents) into pods or add default resource limits.
How They Work
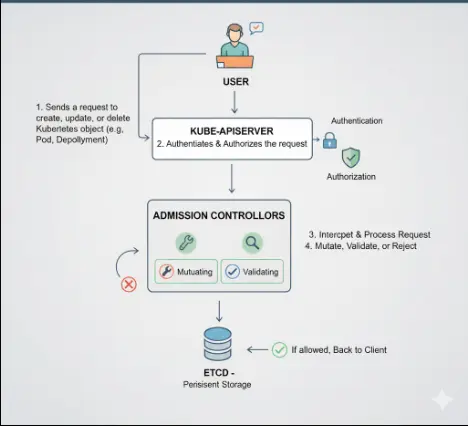
- A user sends a request to create, update, or delete a Kubernetes object.
- The API server authenticates and authorizes the request.
- Admission controllers intercept the request.
- Controllers mutate, validate, or reject the object as needed.
- If allowed, the API server stores the object in etcd.
Custom Resource Defination
A Custom Resource Definition (CRD) is a Kubernetes object that defines a new resource type, specifying its schema, API group, and version. Once a CRD is registered with the API Server, you can create instances of the custom resource (called Custom Resources, or CRs) and manage them using kubectl or other API clients. CRDs are paired with controllers (often implemented as Operators) that watch these resources and take actions to reconcile the cluster’s state with the desired state defined in the CR.
How CRDs Interact with the API Server
When you create a CRD, the API Server registers it as a new API endpoint (e.g., /apis/example.com/v1/databases). Here’s how it works:
- CRD Registration: You apply a CRD YAML to the API Server, defining the resource’s structure and metadata.
- API Extension: The API Server creates a new endpoint for the custom resource, making it accessible to clients.
- Request Processing: Requests to create, update, or delete CRs go through the same API Server pipeline as native resources, including authentication, authorization, and admission control (e.g., validation/mutation by admission controllers).
- Storage: The API Server stores CRs in etcd, just like built-in resources.
- Controller Logic: A custom controller watches the API Server for changes to CRs and performs actions (e.g., provisioning a database).
Example: Defining a Database CRD
Let’s look at a practical example of a CRD for managing database instances.
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: databases.example.com
spec:
group: example.com
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
dbType:
type: string
replicas:
type: integer
scope: Namespaced
names:
plural: databases
singular: database
kind: DatabaseThis CRD defines a Database resource in the example.com/v1 API group. You can now create a custom resource like this:
apiVersion: example.com/v1
kind: Database
metadata:
name: my-mysql
namespace: default
spec:
dbType: mysql
replicas: 3Once applied, a controller (e.g., a Database Operator) watches for this Database CR and provisions a MySQL cluster with three replicas.
Relationship Between API Server, Admission Controllers, and CRDs
The Kubernetes API Server, Admission Controllers, and Custom Resource Definitions (CRDs) work together to create a flexible and secure system for managing both built-in and custom resources. The API Server acts as the central hub, receiving and processing all API requests, including those for CRDs, which extend the API to support custom resource types like databases or machine instances. Admission Controllers intercept these requests after authentication and authorization, enforcing policies or modifying objects (e.g., validating a CRD’s fields or injecting defaults) before they’re stored in etcd. CRDs leverage the API Server’s infrastructure to define new resource endpoints, while custom controllers monitor these endpoints to automate tasks. This synergy ensures that custom resources are managed with the same robustness, security, and scalability as native Kubernetes objects, making the API Server a powerful and extensible platform.
Challenges
- High Availability: As the gateway to the cluster, the API server must be highly available. Downtime can cripple operations, making high-availability configurations (like multi-instance setups) crucial.
- Scalability: In large clusters or high-traffic environments, the API server must handle thousands of requests per second without lag. This requires careful resource management and horizontal scaling.
- Security: With its pivotal role, the API server is a prime target for attacks. Encrypting communication, using secure authentication methods, and applying strict RBAC policies are essential.
- Performance Overhead: Features like admission controllers, which validate and enforce policies, can introduce latency. Balancing performance with robust policy enforcement is a common challenge.
Use Cases
- Cluster Management: Administrators rely on the API server to manage nodes, deploy applications, and configure cluster settings.
- Automation: CI/CD pipelines use it to automate tasks like application deployment, scaling, and updates.
- Monitoring and Debugging: Tools like Prometheus and Grafana query the API server for real-time metrics and logs, helping teams diagnose and resolve issues.
- Custom Resources: Developers use the API server to define and manage custom resources, enabling Kubernetes to support unique workloads and scenarios.
Conclusion
The Kubernetes API Server is the cornerstone of every cluster, providing a secure, consistent, and extensible interface for managing both native and custom resources. Through authentication, authorization, validation, and admission controllers, it ensures that only valid and compliant requests modify cluster state. Custom Resource Definitions (CRDs) further extend Kubernetes’ capabilities, allowing developers to define new resource types while leveraging the same robust API infrastructure. By understanding the interplay between the API Server, admission controllers, and CRDs, administrators and developers can effectively automate deployments, enforce policies, and scale their clusters confidently. Mastering the Kubernetes API Server is essential for building reliable, scalable, and secure Kubernetes environments.
