
The Container Runtime Interface (CRI) is a plugin that lets the kubelet—a program on every Kubernetes node—use different container runtimes. Container runtimes run containers, which form the foundation of modern applications.
Kubernetes introduced CRI in version 1.5. Before CRI, developers built tools like Docker and rkt directly into the kubelet, which made adding new runtimes difficult. CRI allows Kubernetes to use multiple runtimes, and developers can easily integrate their runtimes with Kubernetes.
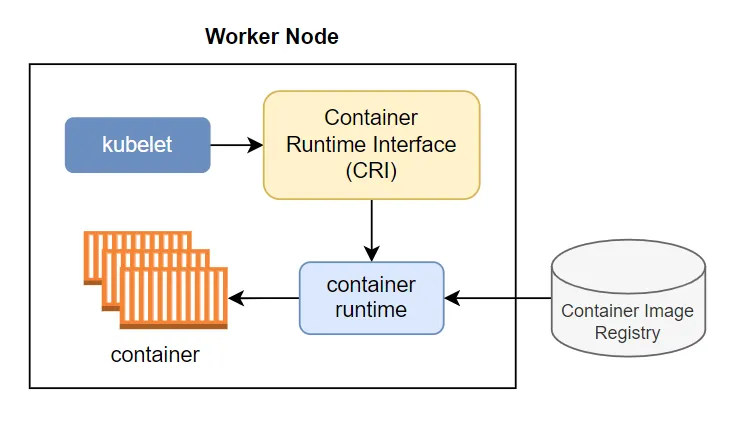
The CRI is a plugin interface which enables the kubelet to use a wide variety of container runtimes, without having a need to recompile the cluster components.
Before diving into the details, a quick reminder of some basic concepts:
- kubelet — the kubelet is a daemon that runs on every Kubernetes node. It implements the pod and node APIs that drive most of the activity within Kubernetes. Kubelet ensures seamless coordination and efficient resource allocation by supporting effective communication between the control plane and nodes, constantly monitoring the containers and engaging in automated recovery to improve cluster resilience.
- Pods — a pod is the smallest unit of reference within Kubernetes. Each pod runs one or more containers, which together form a single functional unit.
- Pod specs — the kubelet read pod specs, usually defined in YAML configuration files. The pod specs say which container images the pod should run. It provides no details as to how containers should run — for this, Kubernetes needs a container runtime.
- Container runtime — a Kubernetes node must have a container runtime installed. When the kubelet wants to process pod specs, it needs a container runtime to create the actual containers. The runtime is then responsible for managing the container lifecycle and communicating with the operating system kernel.
Why CRI was created?
In the early days of Kubernetes, the only container runtime was Docker. Later, Kubernetes introduced rkt as an additional option. However, developers quickly realized that this was problematic:
- Tightly coupling Kubernetes to specific container engines could break Kubernetes, as container runtimes and Kubernetes itself evolved.
- It would be difficult to integrate new container engines with Kubernetes, because this requires a deep understanding of Kubernetes internals.
The solution was clear: creating a standard interface that would allow Kubernetes — via the kubelet — to interact with any container runtime. This would allow users to switch out container runtimes easily, combine multiple container runtimes, and encourage the development of new container engines.
In 2016, Kubernetes introduced the Container Runtime Interface (CRI), and from that point onwards, the kubelet does not talk directly to any specific container runtime. Rather, it communicates with a “shim”, similar to a software driver, which implements the specific details of the container engine.
Kubernetes Before CRI (Container Runtime Interface)
Before the introduction of the Container Runtime Interface (CRI), Kubernetes had tight coupling between the Kubelet and the Docker runtime. This meant Kubernetes could not easily support other container runtimes such as rkt, Hyper.sh, etc. Each time a new container runtime appeared, Kubernetes developers had to modify the Kubelet to communicate with it directly — which was inefficient, error-prone, and hard to maintain.
Situation Before CRI
Initially, Kubernetes used Docker as its default and only supported container runtime. The Kubelet (which runs on each node and manages pods/containers) communicated directly with Docker’s components through custom integrations.
However:
- Each runtime (like rkt, Hyper.sh) had a different API and behavior.
- Kubernetes had to implement custom code for each runtime.
- This led to code complexity, duplication, and maintenance difficulties.
- Adding a new runtime required changes in Kubelet itself, breaking modularity.
Solution — Container Runtime Interface (CRI)
To solve this, Kubernetes introduced the Container Runtime Interface (CRI) — a standard API that allows the Kubelet to communicate with any container runtime through a common interface.
This decoupled Kubernetes from specific runtimes like Docker, enabling support for pluggable runtimes (e.g., containerd, CRI-O, frakti, etc.) without changing the Kubelet codebase.
The diagram represents the internal structure of Kubernetes when it relied heavily on Docker before CRI was introduced.
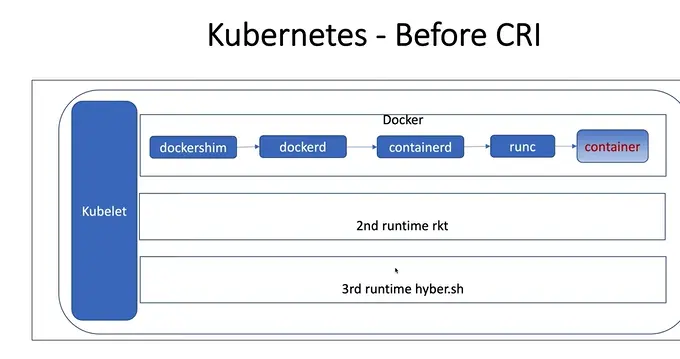
1. Kubelet
The Kubelet is the main Kubernetes agent running on every node in a cluster. Its job is to communicate with the Kubernetes API Server to understand what pods (groups of containers) should be running on that node. The Kubelet ensures that these containers are running and healthy, and it also reports the status of the node and containers back to the control plane.
Before CRI was introduced, Kubelet was tightly integrated with Docker. It couldn’t directly communicate with other container runtimes (like rkt or Hyper.sh) because its logic was written specifically for Docker APIs. To handle Docker, the Kubelet used an intermediary component called Dockershim, which acted as a bridge between Kubelet and Docker.
2. Dockershim
The Dockershim was a special adapter or “shim” built inside the Kubelet to help it communicate with the Docker runtime. It converted Kubernetes’ high-level container management instructions (like creating pods or pulling images) into Docker’s API calls. Without Dockershim, the Kubelet couldn’t understand how to talk to Docker directly.
However, this design made Kubernetes dependent on Docker’s internal architecture. Any time Docker changed its API or behavior, Dockershim had to be updated. Moreover, to support new runtimes like rkt or Hyper.sh, Kubernetes would need to build new shims, one for each runtime — which was inefficient and hard to maintain.
3. Docker Daemon (dockerd)
The Docker Daemon, or dockerd, is the central background process that manages all Docker containers on a host machine. It listens to Docker API requests and performs essential tasks such as pulling container images from registries, creating and starting containers, managing container networking, and handling volumes.
In this pre-CRI setup, once Kubelet (via Dockershim) sent commands, dockerd processed them and coordinated with its internal components like containerd to actually create and manage the containers. This multi-layered process added complexity and additional overhead.
4. Containerd
Containerd is a lightweight, lower-level container runtime that handles the entire container lifecycle — from pulling images to managing running containers. It sits beneath dockerd in the Docker architecture.
In the pre-CRI Kubernetes workflow, once dockerd received instructions from Dockershim, it delegated container management tasks to containerd. Containerd then took care of setting up the container’s environment, downloading images, and supervising the containers’ state. However, at this stage, containerd was not directly used by Kubernetes — it was hidden behind Docker.
5. runc
runc is a command-line tool and low-level runtime that actually creates and runs containers based on the Open Container Initiative (OCI) runtime specification. It is responsible for the final step — launching containers in isolated environments using Linux features like namespaces and control groups (cgroups).
When containerd was instructed to start a container, it invoked runc, which then set up the container process at the operating system level. Essentially, runc is the component that physically “runs” your container.
6. Container
The container is the final product of this chain — a running instance of your application, isolated from the host system but sharing its kernel. Containers contain everything an application needs: the code, libraries, and environment variables.
In this pre-CRI model, the path to create a single running container was long and complex:
Kubelet → Dockershim → Dockerd → Containerd → Runc → Container.
This chain made Kubernetes dependent on Docker’s internal layers and reduced efficiency.
7. Other Runtimes (rkt and Hyper.sh)
At the time, alternative container runtimes like rkt (developed by CoreOS) and Hyper.sh (which used lightweight VMs for better isolation) also existed. These runtimes were not part of Docker’s ecosystem and had their own unique APIs and architectures.
However, since Kubelet only knew how to communicate with Docker (via Dockershim), it couldn’t easily support these other runtimes. To use rkt or Hyper.sh, Kubernetes developers would have needed to write entirely separate integration logic into the Kubelet for each runtime. This lack of standardization was a major problem, leading to fragmentation and maintenance challenges across Kubernetes clusters.
Architecture Of CRI
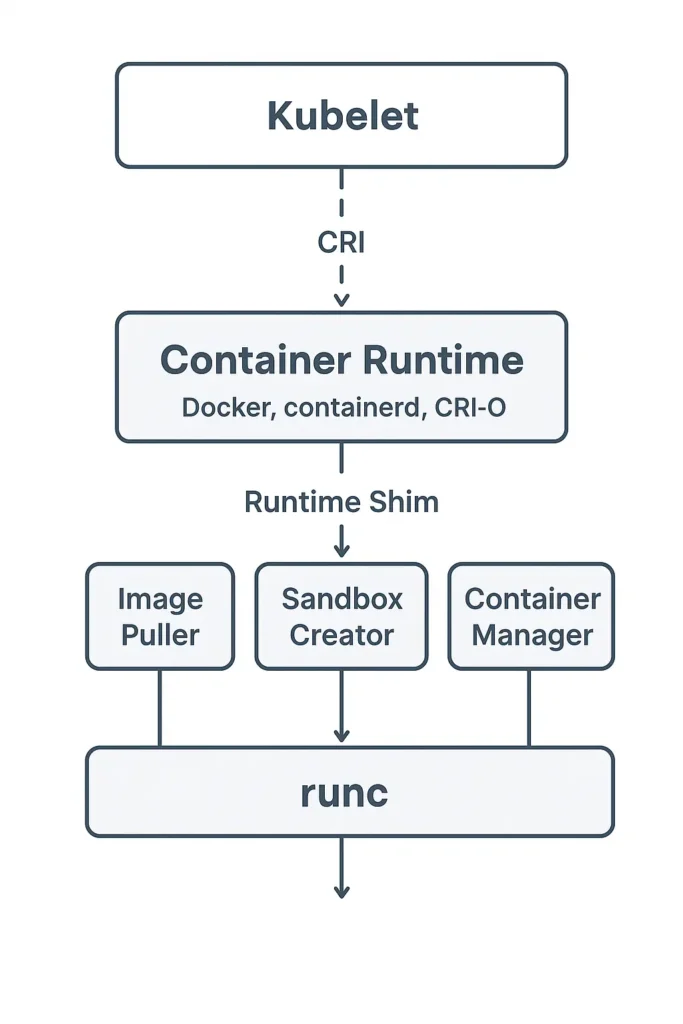
1. CRI (Container Runtime Interface)
The CRI acts as a bridge or communication contract between the kubelet and the container runtime. It uses gRPC (Google Remote Procedure Call) to define two key services:
ImageService – for pulling and managing container images.
RuntimeService – for managing Pod sandboxes and containers.
This standardized interface ensures that Kubernetes can work with different runtimes (Docker, containerd, CRI-O) without changing kubelet code.
2. Container Runtime (Docker, containerd, CRI-O)
This is the core engine responsible for handling all container-related operations. The container runtime performs several key tasks:
- Pulling container images from registries.
- Creating and starting containers.
- Managing container lifecycle and storage.
Some common runtime implementations:
- Docker: The legacy and popular runtime, though Kubernetes now uses containerd underneath.
- containerd: A lightweight runtime built for simplicity and performance, used as Kubernetes’ default in most distributions.
- CRI-O: An open-source runtime developed specifically for Kubernetes, fully compliant with the CRI spec.
3. Runtime Shim
The runtime shim sits between the container runtime and the low-level runtime (like runc). It acts as a mediator that isolates the kubelet and container runtime from container execution details.
Its responsibilities include:
Managing container I/O and lifecycle independently from kubelet and Ensuring that containers continue to run even if the container runtime process restarts.
In containerd’s architecture, for example, this component is called containerd-shim.
4. Image Puller
The Image Puller is responsible for fetching container images from registries such as Docker Hub or a private repository. When a Pod is scheduled, kubelet requests the runtime to pull the required image through the CRI’s ImageService. Once pulled, the image is stored locally for reuse, reducing network overhead.
5. Sandbox Creator
Every Pod in Kubernetes runs inside its own network namespace, called a sandbox. The Sandbox Creator sets up this environment.
It ensures:
Each Pod has its own isolated network stack (using the Container Network Interface – CNI).
The Pod’s containers share this namespace for intra-pod communication.
This sandbox typically includes an infrastructure container (sometimes called the pause container) that holds the network namespace for the Pod.
6. Container Manager
Once the sandbox is ready, the Container Manager handles the actual creation, starting, stopping, and deletion of containers inside that sandbox. It monitors the container lifecycle, resource limits (CPU, memory), and restarts containers if they fail—based on the Pod’s restart policy.
7. runc
At the bottom of the stack is runc, the low-level container runtime that directly interfaces with the Linux kernel to create and manage containers. It implements the Open Container Initiative (OCI) specification, which defines how containers should be created, configured, and run.
runc handles the system-level operations such as:
- Setting up control groups (cgroups) for resource isolation.
- Mounting file systems.
- Managing namespaces (PID, network, IPC, etc.).
It’s the actual tool that executes the container processes on your host machine.
Benefits of CRI in Kubernetes
The Container Runtime Interface (CRI) simplifies how Kubernetes interacts with different container runtimes, improving flexibility, stability, and maintenance across clusters.
Easy migration:
Clusters can switch or upgrade container runtimes without major reconfiguration.
This flexibility ensures smooth runtime transitions and long-term adaptability.
Pluggable runtimes:
CRI enables kubelet to work with any container runtime like Docker, containerd, or CRI-O without altering Kubernetes code.
This modularity allows users to choose or switch runtimes easily based on workload requirements.
Simplified maintenance:
CRI uses standard gRPC APIs, which streamline communication between kubelet and runtimes.
It reduces code duplication and makes integrating or updating new runtimes simpler and faster.
Better stability:
By defining a consistent interface, CRI ensures uniform behavior across all runtimes.
This consistency prevents runtime-specific bugs and increases cluster reliability.
Decoupling from Docker:
Kubernetes no longer depends on Docker’s internal components or APIs.
This separation minimizes compatibility issues and allows kubelet and runtimes to evolve independently.
Security and innovation:
CRI supports next-generation runtimes like Kata Containers and gVisor.
These provide stronger isolation and enable secure, sandboxed environments for sensitive workloads.
Reduced overhead:
With direct communication between kubelet, CRI, and runtimes, extra layers like Dockershim are removed.
This leaner workflow improves startup times, resource efficiency, and overall performance.
Conclusion
The introduction of the Container Runtime Interface (CRI) marked a major milestone in Kubernetes’ evolution. By decoupling the kubelet from specific container runtimes, Kubernetes became more modular, flexible, and easier to maintain. This open interface empowers developers to choose from multiple runtimes—such as containerd, CRI-O, and gVisor—based on performance, security, or workload needs.
Ultimately, CRI transformed Kubernetes into a runtime-agnostic platform, promoting innovation and long-term stability across diverse container ecosystems. It not only simplified runtime management but also paved the way for a more scalable, secure, and future-proof container orchestration system.
